 +
+Cette dernière semaine, j'ai pris un vol easyjet, un vol airfrance, un train italien et un train français. Cela fait donc 4 billets de transport que j'ai pris sur internet. Si je ne voulais pas les imprimer, je pouvais les utiliser directement sur mon smartphone, à condition d'utiliser l'application associée. Je ne sais pas comment fonctionne trenitalia et airfrance, mais pour la SNCF et easyjet, chacun oblige à installer son application.
+ +J'ai donc le choix entre imprimer 4 billets inutilement (juste pour avoir un QRCode qui pourrait être facilement scanné sur mon smartphone) ou à devoir installer au moins deux applications : celle d'easyjet et celle de la SNCF.
+ +Pourtant, ces applications font exactement la même chose que ce que je peux déjà faire sur mon téléphone : elles affichent un QRCode ! J'ai déjà un lecteur de fichiers PDF et la galerie d'images sur mon smartphone, alors, pourquoi devrais-je en installer deux autres ?!
+ +Bref, il est vraiment dommage que chacun reste dans son coin, avec son application propriétaire, disponible uniquement sur le store officiel (et donc nécessitant un compte Google sur Android) et tout ça pour proposer une fonctionnalité qui existe déjà sur mon téléphone ?! Enfin, aujourd'hui, si tu n'as pas ton application attitrée qui vient encombrer l'écran d'accueil de l'utilisateur lambda, tu n'es rien… Tant pis, qu'on garde ces applications, mais qu'on laisse aussi les gens utiliser un format universel et leur smartphone comme ils l'entendent pour afficher le QRCode nécessaire ! Surtout que l'utilisateur a bien souvent l'e-mail avec la confirmation et le billet en PDF dans ses e-mails.
+ +P.S. : Peut être que l'utilisation de l'application dédiée n'est pas nécessaire… Officieusement en tout cas. Mais sur le site de la SNCF (et d'easyjet), on ne parle que de deux possibilités : l'impression papier et l'utilisation de l'application dédiée, en spécifiant que le billet n'est pas valide pour toutes les autres utilisations.
+ +EDIT : Apparemment, pour le contrôle à bord du train, tant qu'on peut présenter le code, éventuellement sur son smartphone, c'est bon. Par contre, ce n'est pas indiqué sur les conditions d'utilisation, et je ne sais pas si c'est officiel…
diff --git a/samples/astuces_arduino.html b/samples/astuces_arduino.html new file mode 100644 index 0000000..d542780 --- /dev/null +++ b/samples/astuces_arduino.html @@ -0,0 +1,26 @@ + +Voici astuces en vrac pour Arduino que j'ai découvertes ces derniers jours, en codant pour CitizenWatt et en particulier pour le capteur.
+ +Il peut arriver d'avoir pas mal de données statiques dans un programme et donc d'arriver à court de RAM disponible (2ko sur un ATMega 328p / Arduino Uno). Et quand ça arrive, c'est le drame (typiquement, le Serial se mettait à faire n'importe quoi dans mon cas)…
+ +Par exemple, à chaque appel de Serial.println("Quelque chose");, la chaîne de caractères "Quelque chose" est chargée en RAM. Du coup, sur un code assez long, avec pas mal d'affichage verbeux sur la liaison série, on sature vite la RAM.
+ +Qu'à cela ne tienne, il est possible de stocker la chaîne dans la Flash et de la charger directement depuis la Flash. Avant, c'était compliqué, il fallait utiliser PROGMEM, mais depuis la version 1.0 de l'IDE, il suffit d'entourer la chaîne de F(), par exemple Serial.println(F("Quelque chose"));. Source
+ +Et au passage, un petit bout de code pour savoir combien il reste de RAM disponible.
+ + +Je n'avais jamais été faire un tour dans les préférences de l'IDE non plus, principalement par flemme. Qu'à cela ne tienne, c'est désormais chose faite, et j'y ai croisé quelques options vraiment vitales.
+ +En particulier, Afficher les résultats détaillés pendant compilation qui permettra d'avoir un output plus verbeux pendant la compilation.
+ +Mais la vraie révélation de cette soirée, c'est l'option Utiliser un éditeur externe. Vous ne supportez plus l'éditeur Arduino et son indentation pourrie, ses fonctionnalités dignes de notepad premier du nom et son non affichage des numéros de ligne (à part en bas dans un petit coin, inutilisable au possible pour débugger efficacement), cette option est faite pour vous ! En l'activant, Arduino ne lira plus le fichier. Vous pouvez l'éditer comme vous voulez dans un éditeur externe (Vim <3) et au moment d'uploader le code, l'IDE Arduino ira relire le fichier, le compiler et l'uploader.
diff --git a/samples/autohebergement_updated.html b/samples/autohebergement_updated.html new file mode 100644 index 0000000..74a3358 --- /dev/null +++ b/samples/autohebergement_updated.html @@ -0,0 +1,13 @@ + +Juste un (très) court article pour signaler que je me suis (enfin) décidé à vider ma todo-list. En particulier, je viens de reprendre ma page sur l'autohébergement que je n'avais pas terminée et qui trainait sur mon serveur. J'ai déjà commencé par rajouter un peu de CSS, et rien que ça, ça change tout ! :)
+ +Cette page doit me servir de mémo si j'ai besoin de réinstaller mon serveur et fournit tout un tas de lien et d'astuces diverses pour quiconque voudrait se lancer dans l'autohébergement. Je la mettrai à jour au fur et à mesure des évolutions sur mon serveur et des nouveaux scripts que je découvrirai.
+ +Cette page va de pair avec les tags AutoHébergement et Serveur sur mon shaarli.
+ +En espérant que ça serve à quelqu'un (et puis sinon, tant pis..., ça me servira toujours à moi :)... (n'ayant volontairement pas de stats sur mon serveur, je ne sais pas si ça servira à quelqu'un ou pas :)
diff --git a/samples/benchmark_rss.html b/samples/benchmark_rss.html new file mode 100644 index 0000000..6579e11 --- /dev/null +++ b/samples/benchmark_rss.html @@ -0,0 +1,69 @@ + +EDIT: I just realized that the PHP function microtime does not return what I expected. This does not change much the results (to compare the solutions) but change the units. I update the results accordingly.
+ +As I wrote in a previous article. I am working on a rss reader that could fit my needs. For this purpose, I am currently trying to see which way is the best way to parse RSS and ATOM feeds in PHP.
+ +I searched on the web for benchmarks, but I could only find old benchmarks, for old version of the libs and weird stuff (like parsing directly the feed with regex). So, I did a quick and dirty benchmark (and this is the reason why this article is in english :).
+ +I searched on the web for the available solutions. I found three main solutions (ordered from the most lightweight one to the less lightweight one):
+My goal was just to do a quick benchmark, so it is complete dirty and may not be very precise, but I did not need more. I did not test extensively all the available libs, especially all the wrappers around SimpleXML as the one I found was sufficient, and is basic enough to reflect a general result.
+ +My test lies on six RSS and ATOM feeds (both of them, to be sure that the lib worked on them) with a total of 75 articles. I parse them with the corresponding lib, and I do not display anything but the total time to parse them. I do not mind the ability of the lib to handle specially malformed feeds as these should not exist and parsing them may encourage their use. So, I am just interested in the time needed to parse these 6 feeds.
+ +The three libs parsed all of them successfully. I ran the test on my laptop, which can be considered almost 100% idle.
+ +The results are:
+| feed2array (and similar basic simpleXML based solution) | +about 40ms | +
| lastRss | +about 120ms and I got some mistakes | +
| SimplePie | +about 280ms | +
So, for my personnal case, I would simply say “the simpler the better” and go for feed2array that works perfectly on the feeds I want to use and is way faster than the overkill libraries. Very often I read that SimplePie was heavy and slow (despite their advertisement as “super fast”) and it seems to be confirmed by my results.
+ +In conclusion, however these results are just to be considered as orders of magnitude, and not precise measurements, I would say that you should avoid any complicated and overkill library unless you really need some of the advanced features it has. Your script will be way faster (up to 5 times faster or so according to these results).
+ +Note: I only focused on these three libraries as it appears that they are the three main libraries available for this purpose (except for feed2array for which there are plenty of similar scripts). I wanted only scripts under a fully open source license, which eliminated some of the others. The only notable ones that I could have taken into account (I think) are the feed library from Zend, but I did not want to search for a way to get only the relevant functions from Zend, and the newly integrated PHP extensions such as XSLT. However, these PHP extensions are not widely available, and not built-in at all, so they may not be available on most of the shared hostings.
+ +Next question I had was how do this time compare with retrieving infos from a database. For this purpose, I compared three times:
+As we could expect, it is longer to parse the feeds than to load them from a storage. So, it is definitely not a good idea to parse them at each page generation. Plus RSS format is not practical at all to do search and complex queries.
+ +The legit solutions are then to use flat files or a database. The difference between the two times is not so large, considering that files are gzipped and that I actually stored a bit more information in the file than in the table.
+ +However, there is not much optimization to do with files, whereas there are many ways to improve my results with a database. For instance, I used a basic sqlite table, without any potential optimization. But I could have used a more robust solution. If performances are really a concern, I could even use a temporary database, stored in RAM, to store the feeds elements. If this table is lost, that is not a big deal, as I will only have to do a refresh to get them back.
+ +Finally, one of the major problems with SQLite seems to be that it may be slow to write and completely locks the database when writing inside. But, this is also the case for flat files.
+ +In conclusion, I would say that the best solution appears to be SQLite with PDO. Actually, the use of PDO will enable to change the database very easily, and SQLite might be as good (if not better) as flat files.
+ +Note: I put all my code and the test rss feeds in a zip archive available here.
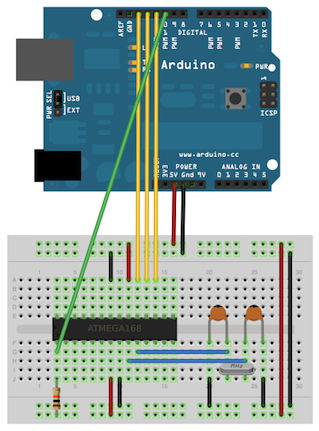
diff --git a/samples/bootloader_atmega.html b/samples/bootloader_atmega.html new file mode 100644 index 0000000..38a3ec5 --- /dev/null +++ b/samples/bootloader_atmega.html @@ -0,0 +1,32 @@ + +Pour un projet avec mon hacklab hackEns (éclairage de façades avec des LEDs de puissance, dans la même veine que AllColorsAreBeautiful du CCC, voir cette page pour plus d'infos), on a eu besoin de graver 30 bootloaders sur des ATmega8. On n'a pas de programmateur et on le fait donc avec des Arduinos. Comme toujours, il nous a fallu 2h de debug avant de graver le premier :) (mais cette fois, ça a été rentable avec 30 bootloaders gravés d'un coup !).
+ +Du coup, je fais une petite compil' des liens qui marchent et des trucs importants à vérifier pour ne pas perdre deux heures (les messages d'erreur du soft Arduino étant *tellement* explicites... et il y a 10 méthodes différentes, chacune aboutissant à une erreur différente sur le net).
+ +Tout d'abord, un bon lien qui marche bien : ArduinoToBreadboard dans la doc Arduino. Les montages sont clairs et ont été testé par moi-même ces derniers jours :).
+ +
+
+
+ 
 +
+
ip link set up dev enp4s0f2
+ip addr add 192.168.192.1/24 dev enp4s0f2
+option domain-name-servers 8.8.8.8, 8.8.4.4;
+
+option subnet-mask 255.255.255.0;
+option routers 192.168.192.1;
+subnet 192.168.192.0 netmask 255.255.255.0 {
+ range 192.168.192.10 192.168.192.20;
+}
+iptables -A FORWARD -o wlp3s0 -i enp4s0f2 -s 192.168.192.1/24 -m conntrack --ctstate NEW -j ACCEPT
+iptables -A FORWARD -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
+iptables -A POSTROUTING -t nat -j MASQUERADE
+echo 1 | tee /proc/sys/net/ipv4/ip_forward
+Ça faisait quelques mois que je disais que j'allais m'héberger une instance de Diaspora* (un pod comme ça s'appelle). Finalement, sous la pression de tmos j'ai cédé et j'ai fini par m'occuper de ça ce weekend. Du coup, il est temps de faire un petit retour sur l'installation.
+ +Note : Je ne m'attarderai pas sur l'historique et le but du projet (TLDR; un réseau social décentralisé et opensource), d'autres l'ont déjà fait, ni sur l'utilisation, car je débarque et n'ai pas encore appréhendé la bête. C'est donc juste un retour sur l'installation, l'accessibilité de Diaspora* au plus grand nombre, et les premiers pas. De plus, je n'ai pas de commentaires sur ce blog statique, donc n'hésitez pas à me contacter pour en discuter.
+ +Il y a peu, Maniatux écrivait « Diaspora, c'est pas pour moi ». J'y suis, j'ai réussi à l'installer, mais je serai bien tenté de dire « Diaspora*, c'est pas pour tout le monde » voire même « Diaspora*, si tu n'es pas geek barbu libriste, mieux vaut passer ton chemin » (pour l'instant, j'espère). Retour sur les principaux points.
+ +Forcément, on parle de réseau social décentralisé, libre et on soulève plusieurs problématiques de vie privée avec les grands réseaux sociaux actuels (Twitter, Facebook, …). Donc si on passe sur Diaspora*, ce n'est pas a priori pour aller sur un pod pré-existant, et retomber dans un silo.
+ +Attention, je ne dis pas que c'est le mal absolu que d'aller sur un pod hébergé par quelqu'un d'autre, loin de là. On a une certaine qualité de service garantie et les principaux pods français (diaspora-fr.org, FramaSphère, …) sont aux mains d'association auxquelles je fais infiniment plus confiance qu'aux gros du web. Mais tant qu'à être présent sur ce réseau, et si on en a la possibilité, autant s'héberger soi-même. Comme j'héberge déjà mon compte Jabber et plusieurs autres services que j'utilise, autant essayer de continuer dans la décentralisation et héberger son propre pod.
+ +La majeure partie des commentaires dans la suite sera donc liée à cet auto-hébergement. Si vous êtes sur un pod hébergé par quelqu'un d'autre, vous ne les rencontrerez sûrement jamais mais ils sont à mon avis très importants pour un projet qui promeut la décentralisation.
+ + +Diaspora a fait le choix d'utiliser Ruby, et non PHP qui est un langage très standard, déjà largement utilisé par Wordpress et tous les autres grands CMS. La plupart des utilisateurs a l'habitude de ces scripts et sait les installer facilement : une base de données créée avec PHPMyAdmin, un copier/coller avec un FTP ou SCP et éventuellement un petit vhost et ça marche. Faire le choix d'un langage « exotique », c'est se priver d'office d'un nombre conséquent d'utilisateurs, qui ne pourront pas l'installer facilement (ne serait-ce que parce qu'ils n'ont qu'un hébergement web et pas un serveur dédié).
+ +Ce choix est très certainement techniquement justifié (PHP est décrié par beaucoup), mais le fait est que Ruby, c'est compliqué à utiliser pour un utilisateur moyen. Il faut installer la bonne version, les bonnes gems, avoir les bons droits etc. Heureusement, Diaspora* utilise RVM qui simplifie grandement l'installation… quand ça fonctionne (j'y reviens un peu plus bas). Enfin, RVM simplifie l'installation, mais la rend d'autant plus obscure : on enchaîne les commandes listées sur le wiki, sans vraiment savoir ce qu'elles font et on passe un temps important à les décrypter pour comprendre ce qu'il va se passer. Dans tous les cas, Node.JS et Python sont déjà largement utilisés (avec des problèmes similaires cependant), les utiliser aurait déjà pu faciliter l'accès et augmenter la documentation disponible.
+ +Note : Diaspora* utilise aussi Node.JS, mais « caché » derrière du Ruby. On est donc surtout confronté aux problèmes avec Ruby.
+ +Enfin, toutes ces technologies (Node.JS / Python / Ruby / …) ne s'interfacent pas directement avec Apache. Là où pour servir un script PHP, il faut tout au plus un vhost, il faut ici charger tout un tas de modules spécifiques pour Apache et servir via mod_proxy l'instance de Diaspora*. Chance, le vhost disponible sur le wiki fonctionne directement, mais je ne doute pas que les nombreuses instructions avancées utilisées décourageront bon nombre d'utilisateurs de comprendre ce que fait réellement ce vhost (ce qui est fort dommage).
+ +C'est donc à mon avis un gros point faible du projet (et je rejoins donc Maniatux), que de reposer sur Ruby, qui est un langage quand même assez exotique, qui empêchera les possesseurs d'un hébergement web seul de l'installer chez eux. Qui plus est quand d'autres technos comme Node.JS et Python sont disponibles, et avec beaucoup plus d'utilisateurs pour aider sur les problèmes généraux et non spécifiques à Diaspora*.
+ + +Diaspora* utilise Ruby, mais ce n'est pas la seule technologie moderne utilisée. On retrouve toutes les technos qui ont le vent en poupe : Node.JS, Boostrap, SASS, YAML, redis… Du coup, à chaque techno, une installation de paquets supplémentaires (redis par exemple), et un frein à la customisation (Bootstrap / SASS par exemple).
+ +Heureusement, les dépôts Debian sont bien fournis, et on peut désormais utiliser des paquets tout prêts pour redis et nodejs. Ça rajoute une étape à l'installation, et élimine définitivement les possesseurs de mutualisés, mais ça n'est pas la partie la plus compliquée.
+ +Les fichiers de configuration YAML sont très bien commentés et lisibles, c'est pratique. Par contre, l'utilisation de SASS oblige à connaître un minimum le fonctionnement de cet outil, et à compiler à chaque fois sa feuille de style. Je ne sais pas si les fonctions avancées de SASS simplifient grandement les feuilles de styles, mais la bidouillabilité en prend un coup =(.
+ + +Sur la documentation, rien à redire. La page de documentation pour Debian Wheezy est complète.
+ +Par contre, la documentation est minimale. Comprenez bien qu'elle est complète donc contient toutes les commandes nécessaires pour s'en sortir et installer Diaspora*, mais ne contient rien de plus. Que faire après l'installation ? Quelques vagues liens sont disponibles en fin de page, mais il faudra se lancer dans l'exploration de son instance (quelques infos sur la façon de fermer son instance aux inscriptions, quelques informations pour faire ses premiers pas auraient été super). Un problème en marge de l'installation, une configuration un peu exotique ? Il faudra vous débrouiller par vous-même.
+ +Et se débrouiller par soi-même, c'est justement ça le problème. La doc sur RVM est assez minime, les chans IRC sont déserts (ou plus exactement il y a du monde, mais aucune activité visible)… (Merci au passage à Flaburgan qui a été un des seuls à répondre :)
+ +En particulier, j'ai eu des problèmes avec RVM. Je n'avais pas sudo disponible sur mon serveur, et selon la documentation, je devais lancer rvm autolibs read-only. Mais cette commande me retournait un magnifique rvm_debug: command not found, quoi que je fasse et bien que tous les fichiers nécessaires aient été sourcés par bash (visiblement, il y avait un problème à ce niveau quand même). Du coup, je cherche cette erreur dans Google mon moteur de recherche favori, et je ne trouve qu'une issue vieille de 6 mois et corrigée. Je reteste plusieurs fois, en suivant scrupuleusement la doc de RVM (cette fois) et non celle de Diaspora* des fois qu'elle ne soit pas à jour. Rien à faire, toujours la même erreur. Je décide donc d'aller voir sur IRC, sur #diaspora et #rvm, aucune activité en 2 jours… Finalement, j'ai réussi à m'en sortir en bidouillant avec un export -f rvm_debug et j'ai réussi à installer Diaspora*, mais je ne sais toujours pas ce qu'il se passait…
Quand on lit les pré-requis dans le wiki, on trouve qu'il faut au minimum 512Mo de RAM (et 1Go de swap) et un CPU multi-cœur. Ces pré-requis sont à destination des gens souhaitant héberger un pod de taille moyenne. Étant le seul utilisateur de mon pod, Diaspora* consommera sûrement beaucoup moins de ressources, à voir. Sinon, ça veut dire que Diaspora* ne pourra pas tourner sur un Raspberry Pi (par exemple), ce qui peut être dommage quand on voit que Cyrille Borne installe un petit serveur XMPP sur son Raspi et qu'une instance de Diaspora aurait pu le rejoindre pour faire un Raspberry Pi social qui contrôle notre identité sur les réseaux.
+ + +On retrouve les principaux éléments des réseaux sociaux traditionnels. L'interface m'a un peu rappelé (feu) StatusNet (ou plus exactement son successeur, pump.io, la faute à Bootstrap je suppose). On arrive sur une vue des derniers posts très classique et on peut poster directement.
+ +Diaspora* met l'accent sur le contrôle de ses données, à travers les aspects (équivalents aux cercles de Google+ je pense). Du coup, chaque post peut être à destination d'un cercle différent, et ce comportement est un peu déroutant au début. En particulier, les posts sont privés par défaut, et il faut commencer à taper son message puis dérouler une liste déroulante pour modifier les aspects qui pourront voir ce post. À noter également qu'une fois un post écrit, son aspect ne peut être modifié.
+ + +Diaspora* met l'accent sur le contrôle des données. Pourtant, je n'ai pas vu de moyen très simple d'exporter ses données (mais je ne doute pas que ça existe), mais surtout pour les importer. On ne peut donc pas migrer son instance sur un autre pod. C'est dommage, j'aurais bien testé sur un pod hébergé avant de passer chez moi =(.
+ +EDIT Autre truc un peu énervant. Quand on cherche un utilisateur, le moindre espace en trop dans le champ de recherche empêche la recherche de s'exécuter correctement.
+ +Je cherchais hier un moyen de générer une belle doc PHP, à partir de mes fichiers sources. Je connaissais quelques outils de la sorte (OcamlDoc, Sphinx pour Python, JavaDoc etc.) mais je n'avais jamais regardé ça en détails.
+ +Du coup, je suis tombé sur Doxygen, qui supporte une très grande variété de langages, est utilisé par beaucoup de scripts (dont des très gros comme Drupal) et était largement suffisant pour mes besoins. Il mange vos sources et génère de belles documentations des pages de doc lisibles, en HTML, LaTeX, CHM et autres.
J'ai pas trouvé de guides ultra rapides pour démarrer (ok, j'ai pas vraiment cherché non plus) donc je liste ici les 3 commandes de base, pour avoir une doc en 5 minutes chrono.
+ +Pour commencer, il faut faire doxygen -g .doxygen dans le répertoire du projet pour générer un fichier de configuration (option -g) nommé .doxygen. Voici quelques paramètres utiles à modifier:
+Une fois tout ceci fait, il faut que vos commentaires soient au bon format pour que doxygen les lise. Un exemple est disponible ici.
+ +En gros, il faut à chaque fois redoubler les commentaires /** … */ pour que doxygen les parse. Les premières lignes de texte dans chaque cas sont un petit paragraphe descriptif. Il est possible d'ajouter un plus long paragraphe après avoir sauté une ligne. Doxygen utilise ensuite des tags @quelquechose pour noter les paramètres, les valeurs de retours, les copyrights etc.
+ +Important, ne pas oublier de dire à doxygen d'utiliser le fichier courant avec un @file dans le commentaire global du fichier.
+ +Une fois tous vos fichiers taggés correctement, lancer doxygen .doxygen depuis la racine de votre projet pour générer la doc. Vous obtiendrez une belle documentation comme ça (ok, il y a encore du boulot sur celle-ci…).
diff --git a/samples/eacute_js.html b/samples/eacute_js.html new file mode 100644 index 0000000..f09c2f2 --- /dev/null +++ b/samples/eacute_js.html @@ -0,0 +1,15 @@ + +Pour les besoins d'un plugin pour le thème greeder de Leed (gestion des raccourcis claviers), je devais détecter l'appui sur n'importe quelle touche du clavier en javascript. Pour ce faire, a priori, ce n'est pas très dur, il suffit de surveiller l'événement onkeydown et de récupérer le keycode correspondant. Cette méthode fonctionne sans problèmes sur des claviers azerty / qwerty (tout du moins pour ce que je voulais faire) mais pose de graves problèmes sur des dispositions exotiques type Bépo (ty tmos de me l'avoir signalé :). En effet, ces dispositions possèdent de nombreuses touches particulières, qui ne sont pas traitées par la méthode précédente. Ainsi, il était impossible d'assigner un raccourci à la touche "é" ou "É" par la méthode précédente (pas de problème sur un clavier azerty/qwerty car cette touche est alors détectée comme "2").
+ +Après quelques recherches, j'ai découvert qu'il existait déjà deux moyens de savoir quelle touche était pressée : which et keycode. Dans la majorité des cas, ils fournissent le même résultat, sauf dans le cas qu'on veut justement traiter. Je n'ai pas approfondi la question mais il semble que which est plus général, et d'après mes tests, il fonctionne sur toutes les touches utiles d'un clavier azerty/qwerty/bépo. Attention en revanche, les codes renvoyés par which peuvent différer des keycode pour les caractères exotiques.
+ +Mais cela ne suffisait pas. J'avais beau utiliser which qui devait me retourner un certain code de touche, je n'avais rien. Après quelques tests, je me suis alors aperçu qu'il n'y avait purement et simplement aucun événement lancé lors de l'appui sur la touche fautive...
+ +En effet, il existe encore une fois plusieurs événements disponibles sur l'appui d'une touche. Le plus simple, et le plus naturellement adapté pour détecter des raccourcis claviers est onkeydown, qui n'est émis qu'une seule fois, lors de l'appui d'une touche. Mais cet événement n'est pas déclenché lors de l'appui sur certains caractères spéciaux (dont é). La solution est alors de faire un code légèrement plus lourd en utilisant onkeypress en remplacement. onkeypress est déclenché tant que la touche est appuyée (ce qui veut dire de potentiels événements multiples, contrairement à onkeydown) mais a le mérite de fonctionner avec toutes les touches des dispositions azerty/qwerty/bépo.
+ +En résumé, pour détecter un appui sur n'importe quelle touche du clavier, il faut utiliser l'événement onkeypress et détecter le code de la touche avec which. Cela fonctionnera, en échange d'une légère baisse de performances du script. Dommage que ceci n'ait pas été harmonisé ou simplifié un minimum...
diff --git a/samples/elysee.html b/samples/elysee.html new file mode 100644 index 0000000..d8c513a --- /dev/null +++ b/samples/elysee.html @@ -0,0 +1,72 @@ + +Vous avez sûrement déjà vu un +site officiel sur l'IVG utiliser Google Analytics, ce qui n'est pas sans +poser quelques problèmes d'anonymat et de confidentialité, un cloud souverain mais vous +n'avez sûrement pas encore vu le site de +l'Élysée (en tout cas, moi je ne l'avais jamais vu il y a encore quelques +jours) !
+ +Mais hier, je suis tombé sur cet article +sur le blog webatou qui reportait des +popins sur le site de l'Élysée, comportement assez étonnant pour un site +officiel, qui vante son +accessibilité (mais non, il n'y a bien sûr aucun popin sur cette +page…), qui fait appel à une +société (dont on n'ose même pas imaginer la facture) pour améliorer son +accessibilité. Ok, elle +n'était pas parfaite, mais c'était déjà ça.
+ +Mais alors, que leur a-t-il pris de mettre un énorme popin pour
+les suivre sur Facebook
(sérieusement, la présidence est tellement en
+manque de reconnaissance, qu'il lui faut des likes sur Facebook ?).
+Pas de problèmes, je clos le popin. Prochain chargement, la même chose pour
+Twitter ! Je ferme encore, prochain rechargement, la même chose pour la
+newsletter. Je suis assez grand pour savoir où je veux vous
+suivre tout seul, pas besoin de 3 popins !
Du coup, je me suis penché un peu plus sur le site, et je suis juste +consterné… On passera sur l'enveloppe en haut de page qui n'a rien à voir avec +un quelconque contact, mais permet juste de s'abonner à la newsletter, on +passera sur les mêmes pages qui sont liées à N endroits différents sur le site, +avec un texte différent à chaque fois, idéal pour perdre le visiteur (mais bon, +c'est une spécialité +des services publics apparemment)… Non, ce qui m'a inquiété, c'est +l'origine du petit script JavaScript responsable du popin.
+ +Pas de problèmes, on recharge la page en activant la console de Firefox, et +on découvre qu'il n'y a pas moins de 15 scripts différents chargés (totalisant +un poids voisin de 900ko (oui oui, 900ko soit trois fois plus +que l'image la plus lourde de la page, mais #ToutVaBien), ce qui est finalement +dans la moyenne des pages webs actuelles avec leur tendance à cracher du +JavaScript à la pelle) dont un seul hébergé sur le serveur de +l'élysée.
+ +Oui oui, vous avez bien lu, sur le site de l'Élysée, il y a +14 scripts (soit 93% des scripts) qui viennent d'un serveur +externe (Facebook, google API, Twitter, Typekit et readspeaker). Et je ne parle +que des javascripts, pas des images et des CSS (qui finalement sont presque +tous chez l'Élysée pour le coup). Ça veut donc dire qu'au moins 4 grandes +entreprises américaines peuvent inclure un peu ce qu'elles veulent sur la page +de l'Élysée. Joli !
+ +Enfin, on notera que le seul contact que j'ai pu trouver pour l'équipe +responsable du site de l'Élysée était une adresse postale à l'Élysée, pratique +à l'heure où envoyer un e-mail n'a jamais été aussi simple et rapide.
+ +P.S. (disclaimer) : Pour tous ceux qui chercheront à relever tous les +problèmes d'accessibilité sur mon blog, je sais qu'il est loin d'être parfait, +et il faudra que je m'en occupe quand j'aurai 5 minutes. Sauf que dans un cas +on parle d'un blog personnel, n'ayant aucune prétention particulière, et dans +l'autre cas on parle d'un site institutionnel qui se prétend +modèle d'accessibilité…
diff --git a/samples/fairphone.html b/samples/fairphone.html new file mode 100644 index 0000000..a8d4a5f --- /dev/null +++ b/samples/fairphone.html @@ -0,0 +1,107 @@ + +J'ai acheté un Fairphone en novembre, et je l'ai reçu il y a quelques semaines maintenant. Je n'ai pas encore eu le temps d'écrire dessus, mais c'est désormais corrigé. Ce Fairphone vient remplacer mon ancien Galaxy S3, qui tournait sous Cyanogen 9, mais qui n'a pas arrêté de me poser des problèmes (problème avec la puce son qui se coupait parfois, présent chez de nombreux utilisateurs apparemment, entre autres).
+ +Note : Ceci est un petit compte-rendu après quelques semaines d'utilisation. Je mettrai cet article à jour au fur et à mesure, si de nouveaux problèmes apparaissent ou sont, au contraire, résolus.
+ +

Tout d'abord, qu'est-ce que c'est que cette étrange bête ? Fairphone est une initiative d'un groupe de hollandais pour proposer une alternative plus équitable aux smartphones actuels. Le projet a été crowdfundé pendant un peu plus d'un an, et le premier lot de 25 000 Fairphones a été livré en janvier.
+ +Ils se sont engagés sur un certain nombre de points, parmi lesquels :
+Finalement, on a un smartphone assez similaire au Wiko Cink Five, il me semble, pour 325€, ce qui est certes plus cher, mais n'avance pas les mêmes atouts. Voyons voir ce que vaut le Fairphone après quelques semaines d'utilisation.
+ +Le Fairphone a un écran de 4"3. Ce n'est pas tant que ça pour un smartphone actuel (on est plus autour de 5" aujourd'hui), mais au moins ça rentre dans une poche. Quand je le compare à mon ancien Galaxy S3, il paraît tout petit. De nombreuses personnes préfèrent avoir un grand écran, mais quitte à avoir des écrans de 5" et plus, autant prendre une tablette. En fait, ces tailles me paraissent un peu bancales, à mi-chemin entre un téléphone et une tablette : pas facile à prendre en main d'une seule main, trop petit pour deux mains, pas pratique dans une poche… Finalement, je suis plutôt favorable à une diagonale plus petite. À titre de comparaison, c'est à peu près la même diagonale d'écran que l'iPhone 5 (4") et il a la même taille à quelques millimètres près.
+ +Le design est plutôt soigné et l'appareil est assez joli, avec son liseret blanc et son dos en alu. On notera la présence d'un bouton “Marche/Arrêt” classique au sommet de l'appareil et un bouton de réglage du volume sur le côté. Les trois boutons en façade (Menu / Accueil / Retour) sont en fait des touches tactiles. Elles sont assez jolies, mais on a tendance à les effleurer par inadvertance en tapant des messages. On s'y habitue, mais je préfère clairement avoir des boutons physiques à cet endroit.
+ +Pour une fois, le capot arrière s'enlève assez facilement, contrairement à de nombreux smartphones avec lesquels on a peur de briser la fine couche de plastique qui sert de capot arrière. Derrière, on trouve deux logements pour carte SIM (SIM classique, et non micro-SIM, on dirait que la mode des toutes petites SIM est passée ?), l'emplacement de la batterie et un emplacement Micro-SD pour étendre le stockage de 16Go initial.
+ +Un point négatif quand même : l'appareil photo est légèrement sortant du téléphone. Du coup, quand le téléphone est posé à plat sur une table, il repose sur l'appareil photo, et sur un des coins, mais il manque un troisième point d'appui au même niveau. Conclusion : il est bancal quand il est posé sur une table. C'est dommage car ce n'est vraiment pas grand chose, mais ça complique grandement son utilisation d'une seule main, en le posant sur une table.
+ +
L'écran est de plutôt bonne qualité, avec une bonne résolution (960x540 pixels, pour une densité de 256ppi), similaire au Wiko Cink Peax 2. J'ai eu auparavant un iPhone 4 et un Galaxy S3 et la qualité de l'écran ne me perturbe pas particulièrement (ni en bien, ni en mal), mais mon utilisation n'est peut être pas la plus propice pour juger de la qualité de l'écran ? Je n'ai pas eu l'occasion de le comparer côte à côte avec mon Galaxy (notamment parce qu'avec un écran cassé, le rendu n'aurait pas été à son avantage), donc je ne peux pas en dire beaucoup plus…
+ +En parlant d'écran cassé, l'écran a également une vitre "Gorilla Glass" censée être assez résistante. Ceci dit, cela n'a pas empêché la vitre de mon Galaxy de s'exploser à la moindre chute de 10cm avec une coque de protection :/
+ +Une remarque quand même : l'écran a tendance à garder pas mal les traces de doigt. Plus que le SGS3 en tout cas je dirais.
+ +Un autre point important à noter, pour ne pas être surpris, est la présence d'un réseau de petits points sur l'écran, que l'on voit sous certaines conditions d'éclairage. C'est un peu perturbant au début, car on commence par en voir un, et on pense à un pixel mort. Puis on en voit d'autres, et on finit par se rendre compte qu'ils sont trop bien alignés pour que ce soit un problème. Finalement, on trouve la réponse sur le forum de support Fairphone : il s'agit d'une grille pour l'écran tactile, qui est visible sous certaines conditions d'éclairage. Ils ont dû adopter cette technologie à cause d'un brevet sur les autres solutions. Personnellement, je n'y fais pas particulièrement attention et cela ne me dérange pas et on ne le voit que sous certaines conditions bien particulières (donc pas dérangeant pour des vidéos a priori), mais il faut le savoir pour ne pas être surpris.
+ +Le Fairphone tourne sous une version stock d'Android 4.2.2. Par défaut, aucune application Google n'est installée (libre à vous de les installer au besoin). Personnellement, venant de Cyanogen Mod sur mon Galaxy S3, je suis resté sans applications Google et trouve tout ce dont j'ai besoin sur F-Droid. Les seules applications préinstallées sont :
+Tous ces logiciels sont open-source, iFixIt étant disponible sur F-Droid et les autres étant disponibles sur Github. Je vous laisse d'ailleurs aller voir le dépôt Github pour plus d'images de l'interface et des widgets.
+ +On a donc un système Android de base, avec une très légère surcouche, le tout étant open-source, ce qui est très rare sur les smartphones actuels. Pas d'autres bloatwares que ceux dans Android d'origine donc.
+ +La légère surcouche graphique est très jolie, et va plutôt bien avec le look du Fairphone, à mon avis. Cf cet article sur le flat design chez le hollandais volant, je trouve que le Fairphone n'en est pas trop victime.
+ +

Un des changements apportés par la surcouche graphique est la présence d'un lanceur rapide lorsqu'on touche le bord droit de l'écran (uniquement sur l'écran d'accueil et sur le menu des applications). C'est d'ailleurs grâce à lui qu'on accède à la liste des applications. Il est assez pratique, une fois qu'on s'y est un peu habitué. En effet, au début, on l'appelle souvent sans faire exprès en naviguant dans la liste des applications.
+

P.S. : Parmi les applications de base, on trouve également une application “TODO”, un enregistreur de son, une application pour écouter la radio FM, une application de notes et un gestionnaire de fichier. Me corriger si je me trompe, mais il me semble que ces applications sont intégrées à Android stock.
+ +L'appareil photo me semble raisonnable, même si j'avoue ne pas avoir beaucoup de références en la matière. Par contre, l'application n'arrêtait pas de m'afficher le tutoriel. En fait, il suffit de le suivre en entier (ce qui prend environ 30 secondes), et ensuite vous ne le verrez plus. Sinon, vous pouvez aussi installer l'application Camera stock disponible sur f-droid.
+ +Pour juger plus en détails de la qualité des photos, je vous laisse regarder les photos disponibles ici que j'ai prises avec mon fairphone.
+ +Comme pour de nombreux utilisateurs, le premier fix GPS a été très long à avoir. En fait, je n'ai même pas réussi à l'avoir en intérieur… Mais en activant l'A-GPS, en téléchargeant les données EPO et en faisant un petit tour à pied dehors, le fix GPS est assez rapide (< 5 minutes). Une fois ce premier fix réalisé, mon GPS se fixe quasiment instantanément (< 10 secondes). Voir notamment cette page chez xda-developpers et ce thread sur le forum fairphone pour plus d'informations.
+ +La gestion des cartes SIM diffère un peu de ce que j'avais sur mon Galaxy S3. En particulier, le Fairphone a deux emplacements SIM, et vous affichera donc une notification si vous n'en avez qu'une seule d'insérée. De plus, à chaque sortie du mode avion, votre code PIN vous sera demandé (alors que mon Galaxy S3 ne le demandait qu'une fois par démarrage du téléphone). Enfin, étant chez Free, je suis souvent en itinérance (nationale, sur le réseau Orange). Le Fairphone ne fait aucune différence entre l'itinérance nationale et internationale, et vous aurez donc droit à quelques messages vous prévenant que vous êtes en itinérance sur la carte SIM utilisée et vous demandant de confirmer l'envoi d'un SMS (par exemple). Il est possible de désactiver les confirmations répétées, et il ne restera alors plus qu'une seule alerte à l'envoi d'un SMS à la sortie du mode avion. Il faut également penser à désactiver l'itinérance quand on est à l'étranger du coup, pour éviter les surcoûts.
+ +Je n'ai pas encore eu l'occasion de tester le téléphone avec deux SIMs à la fois, mais a priori c'est très classique. On peut spécifier les cartes SIMs par défaut à utiliser, et la carte SIM utilisée apparaît en encart dans chaque SMS, etc. Je devrais pouvoir le tester d'ici un mois je pense, je mettrai à jour l'article en conséquence.
+ +En conclusion, je suis très satisfait de mon Fairphone. Il est certes un peu plus cher que la concurrence, et présente quelques défauts de jeunesse, mais il me paraît tout à fait raisonnable et une bonne alternative aux autres téléphones des grands constructeurs. Par contre, étant édité à peu d'exemplaires, je doute qu'on voit beaucoup d'accessoires dédiés dans les prochains mois (notamment de housses parfaitement adaptées à son form factor). Je ne suis pas doué pour les conclusions, donc je vous laisse conclure tout seul :)
+ +Note (car il faut bien un peu de troll) : on se rappellera des défauts des problèmes sur les premiers smartphones (et pas que les premiers en fait) des autres constructeurs, notamment l'absence de 3G sur le premier iPhone, ou encore les problèmes d'écran jaune sur l'iPhone 3GS ou récemment sur l'iPhone 5.
+ +Edit : J'ai retrouvé le lien vers l'article sur le site du projet replicant qui parlait de l'open-source et du Fairphone : http://www.replicant.us/2013/11/fairphone/.
+ +Edit 2 : J'ai oublié de parler de la batterie et de l'autonomie… C'est donc réparé avec ce petit rajout. L'autonomie est plutôt bonne, dans la moyenne des smartphones actuels (en tout cas, sensiblement comparable à celle de mon ancien S3). Je tiens une journée (8h -> 24h) en relevant 5 comptes e-mails en push, en allant sur internet dans le bus (1h) et à quelques occasions dans la journée, et en passant la journée dans une zone pas très bien couverte (je finis la journée avec entre 10% et 30% de batterie selon les jours). Bref, comme d'hab', on tient une journée sans trop de difficulté (sauf utilisation ultra-intensive, mais pour ça, on ne peut pas grand chose) mais il faut quand même recharger tous les soirs. En restreignant un peu mon utilisation, je pense que je pourrais tenir deux jours.
+ +Edit 3 : Le blocage complet et le reboot de l'interface sont liés et sont un seul et même problème apparemment. Cela arrive aussi avec le contrôle du volume. Je l'ai eu quelques fois depuis que j'ai mon Fairphone, et c'est assez embêtant comme bug. Mais Fairphone est au courant et le problème devrait être corrigé dans la prochaine mise à jour qui arrivera d'ici peu. De même pour les problèmes d'itinérance nationale qui devraient être résolus bientôt. J'ai également depuis peu une deuxième carte SIM et rien à redire sur la gestion des cartes SIM : on peut choisir la SIM par défaut pour chaque action (SMS, Appels, Internet, …) et la gestion des deux cartes est très complète. Quand à l'autonomie, je tiens toujours un peu plus d'une journée avec mon utilisation. Par exemple, ce soir, j'en suis à 15h sur batterie, 5 comptes e-mails en push toute la journée, une couverture réseau assez aléatoire et 2 à 3h sur Internet en 3G et il me reste encore 22% de batterie.
+ +Edit 4 J'ai envoyé un e-mail pour rapporter les issues remarquées à Fairphone et ils m'ont répondu (avec un peu de retard, mais quand même) qu'ils prenaient note et corrigeraient. Et Fairphone vend des pièces détachées et a mis des guides pour réparer son téléphone.
diff --git a/samples/first.html b/samples/first.html new file mode 100644 index 0000000..b0c85e0 --- /dev/null +++ b/samples/first.html @@ -0,0 +1,21 @@ + +Ça y est, mon blog est enfin en ligne. Depuis le temps que j'ai cette idée en tête (et que la page http://phyks.me affiche un magnifique "Blog coming soon"), j'ai enfin eu le temps de finaliser les deux / trois trucs impératifs avant de le lancer. :)
+ +J'ai donc enfin ma petite parcelle de web où partager diverses astuces sur les trucs que j'utilise quotidiennement (et quelques coups de gueules aussi). Entre autres, des petits trucs sur Arch Linux, sur de la prog, sur l'autohébergement et des trucs en vrac. J'en ai également profité pour mettre en place un shaarli (que j'utilise en fait déjà depuis quelques temps), ici. Il y aura des articles en français (principalement) et quelquefois en anglais quand c'est un truc que je n'ai trouvé nulle part ailleurs.
+ +Pour ceux qui se demanderaient comment fonctionne le blog en arrière-plan, c'est un blog statique sur moteur fait-maison. J'avais eu l'idée de faire un système de blog sur dépôt Git et avait commencé à le coder, avant de me rendre compte que de nombreux projets existaient déjà :/ Bref, ayant la flemme de reprendre un code existant en l'adaptant à mes besoins et ayant déjà commencé à réinventer la roue, j'ai continué mon bout de code, aboutissant à ce blog. Le code est d'ores et déjà disponible sur Github, mais il manque encore quelques fonctions et cette instance sera l'occasion d'un test en grandeur nature. Il sera mis à jour prochainement, quand j'aurai corrigé tous les petits trucs qui ne me plaisent pas et refactorisé un peu le code.
+ +Le blog est donc intégralement stocké sous forme de fichiers html dans un dépôt Git (sur mon petit dédié chez OVH) et un hook lancé au commit s'occupe de générer les fichiers html servis par le serveur web. Les articles sont rédigés de façon très basique en html pour l'instant (mais je prévois d'implémenter une syntaxe à la markdown dans un futur proche), et tout est un peu fait "old school" (pas de formulaire tout joli avec drag&drop pour envoyer des images par exemple, je suis plus efficace sans). Ça peut paraître bancal parfois, mais ça me va bien :) Du coup, pas de commentaires sur ce blog, ne voulant pas ajouter un service externe à la Disqus. De toutes façons, je rejoins l'avis de Bortzmeyer sur la question. J'adore les commentaires constructifs, mais je préfère lire des articles complets sur un blog qu'une réponse en deux lignes en bas d'un article. Si vous voulez commenter, n'hésitez pas à m'envoyer un e-mail ou à me dire si vous réagissez quelque part. :)
+ +P.S. : Merci à sebsauvage, le hollandais volant, idleman, Ploum et tous les autres de la blogosphère française que j'oublie, que je suis depuis quelques temps déjà, plus ou moins silencieusement et qui m'ont donné envie d'avoir mon petit espace à moi aussi !
+ +
Image sous licence CC 3.0 BY NC SA (source)
Note : Je suis en train de tout remettre en place sur mon serveur, suite à une réinstallaton. Mon Jabber, mon serveur Git etc. reviendront donc bientôt, quand j'aurai 5 minutes pour m'en occuper :(
diff --git a/samples/free_mobile_fluctuant.html b/samples/free_mobile_fluctuant.html new file mode 100644 index 0000000..e0f00e8 --- /dev/null +++ b/samples/free_mobile_fluctuant.html @@ -0,0 +1,18 @@ + + +C'est très étrange… Là où je suis, la connexion SSH est toujours utilisable (avec un lag important rendant très insupportable toute édition de fichiers, mais Weechat over SSH est utilisable), mais le débit sur le port 80 est très fluctuant. Quelques fois les pages se chargent très rapidement, quelques fois il n'y a pas moyen de charger une seule page, même après 10 minutes d'attente et trois tentatives (indépendamment du domaine, donc pas un problème de peering a priori).
+ +Par contre, passer sa connexion web dans un tunnel SOCKS améliore grandement les choses. Et de façon générale, j'ai déjà remarqué ça à plusieurs reprises sur des connexion lentes (Free Mobile, mais aussi certains hotspots etc.). À 18h, la connexion est toujours inutilisable, mais ça rend la connexion internet utilisable le reste du temps.
+ +Je précise que je suis dans une zone censée être couverte en H+ (je le cherche encore le fabuleux débit promis par toutes les dernières technos, quand en HSDPA, j'ai tout juste un débit d'EDGE) et encore loin de mon plafond mensuel de 3Go (et de toutes façons, le même comportement est observé avec des clients utilisant peu la 3G)… qu'est-ce que ça va être après ?
+ +Du coup, Free bride-t-il le port 80 ? Ou l'antenne est-elle surchargée (par des gens qui font du web, donc du port 80) ? Ça m'étonne quand même cette différence significative de débit selon les ports utilisés (à titre de comparaison, je ne pouvais pas mettre à jour mon système avec yaourt tout à l'heure, débit trop faible, mais un téléchargement de quelques mégaoctets dans mon Firefox sur proxy SOCKS se faisait en un temps « raisonnable » et je peux récupérer mes emails par POP/IMAP sans problème).
Bref, c'est pas la première fois que je remarque ça, et heureusement j'ai la possibilité de faire un tunnel SOCKS sur mon kimsufi, mais comment fait Madame Michu ?! Et surtout… pourquoi ce comportement si étrange sur le port 80 ?
+ +P.S. : J'ai pensé au début que c'était Orange qui bridait le débit des abonnés Free sur ses antennes, me rappelant d'histoires similaires au lancement, et confirmé par un portable chez Sosh qui tourne sans problème. Mais il semblerait que je sois sur une antenne Free…
diff --git a/samples/hackathon_cc.html b/samples/hackathon_cc.html new file mode 100644 index 0000000..92076fd --- /dev/null +++ b/samples/hackathon_cc.html @@ -0,0 +1,30 @@ + +J'ai reçu aujourd'hui une pub pour hack4france, un « hackathon 100% made in France ». On passera sur le hackathon made in France avec du bon anglais de partout (et oui, aussi surprenant que ça puisse paraître, hack4France, c'est pas du français, en bon français, ça donnerait « hack pour la France », tout de suite moins in), sur les récompenses et sur les APIs proposées pour regarder la FAQ et le règlement qui devraient faire hurler tout défenseur des licences libres. Malheureusement, c'est trop souvent comme ça avec ce genre de hackathons.
+ +Déjà, c'est quoi un hackathon ? L'idée de base est de hacker pendant une journée, pour faire bien avancer un projet ou faire émerger de nouvelles idées. Maintenant, si on lit entre les lignes, le hackathon proposé est plutôt “trouvez-nous un projet innovant et sympa, qui va bien se vendre et en échange on vous donne quelques cadeaux”.
+ +Seul problème : le créateur du projet reste l'auteur et donc garde le copyright. Pas génial comme truc si on veut le reprendre, le modifier de notre côté et se faire plein d'argent avec. Pas de problèmes, on a un truc génial pour ça, la Creative Commons !
+ +Du coup, il est précisé dans le réglement (article 12) que tous les éléments produits (à l'exception du code lui-même) seront sous licence Creative Commons BY, ce qui fait qu'il sera très facile pour eux de le réutiliser, et que « le créateur garantit le Prestataire, et les Entreprises Partenaires contre tout trouble, action, réclamation, opposition, revendication et éviction quelconque provenance d’un tiers. ».
+ +Ok, donc on a un concours, on gagne des trucs et en plus mes créations graphiques (entre autres) sont sous Creative Commons. Malgré l'utilisation quelque peu vicieuse de la Creative Commons, c'est leur droit et le participant est au courant en lisant le réglement qu'il a accepté. À part un problème de morale, il n'y a pas grand chose à en dire. Certes, mais ça, c'est avant d'avoir vu la FAQ.
+ +Notamment dans la partie “Que devient le résultat du hackathon ?”,
+Vous restez l'entier propriétaire du prototype et de son code. Pour plus de précisions, nous vous invitons à lire le réglement du challenge.+ +
Certes, on reste propriétaire du code car on ne peut céder ses droits moraux dans le droit français, mais on remarquera qu'on passe très étrangement sous silence que les productions seront sous licence Creative Commons. Pour plus de précisions, il faut aller se noyer dans le réglement et tomber sur l'article 12.
+ +Plus grave encore, à la question “Dois-je partager mon code ?”, il est répondu que ce n'est pas obligatoire. En effet, je ne dois pas partager mon code, rien ne m'oblige à le partager. Mais rien n'empêche le partage des autres éléments pour autant. Et il faut bien comprendre que tous les autres éléments seront partagés. Et un code n'est pas le plus dur à reproduire une fois qu'on a l'idée et les éléments graphiques.
+ +Tout ça sera déjà partagé entre les juges, et les entreprises qui financent le concours. Si une idée leur plait, pas de doutes qu'elles la récupèront et en feront quelque chose. Mais ensuite, grâce à la licence CC BY, il suffit que n'importe quel membre du jury veuille redistribuer, et il sera dans son droit pour le faire. Tout sauf le code sera alors partagé.
+ +Bref, une utilisation vicieuse des Creative Commons et une FAQ qui omet judicieusement certains éléments…
+ +P.S. : On remarquera qu'ils se sont d'ailleurs judicieusement limité à la CC BY, en excluant toute possible ND, NC ou SA qui aurait grandement réduit l'intérêt du dispositif.
+ +EDIT : Correction d'une erreur qui s'était glissée dans l'article. Le code n'est pas sous licence Creative Commons, mais tous les autres éléments le sont.
diff --git a/samples/highmon_weechat.html b/samples/highmon_weechat.html index 14a3567..c4b33f5 100644 --- a/samples/highmon_weechat.html +++ b/samples/highmon_weechat.html @@ -40,3 +40,12 @@You can now clear the hilight window with /clear_highmon and scroll in it with the other aliases. So, I think you are good to go for a (quite) perfect weechat setup :)
+ +Update:
+/key bind KEY /scroll_highmon+ where KEY is some key or combination of key (for instance meta-meta2-A or whatever you want). You can do the same for /clear_highmon and /scroll_highmon_up. +
Il m'arrive souvent de corriger des documents textes et de devoir noter facilement les fautes d'orthographe. Idéalement:
+Une solution est de corriger directement le document, puis de faire un diff. Ça marche, mais ce n'est pas des plus pratiques (on n'a pas forcément diff partout par exemple, ou encore le texte source n'est pas disponible pour du Markdown ou du LaTeX) et c'est quand même pas le plus lisible pour le destinataire. Pour résoudre ce problème, on peut utiliser etherpad (dont une instance est disponible chez FramaSoft pour ceux qui ne veulent pas auto-héberger) par exemple, qui va garder les corrections en couleur et ce sera donc très lisible.
+ +Ceci dit, j'utilise une autre solution, qui ne nécessite qu'un éditeur de texte brut, et qui, un peu comme Markdown, est facilement lisible par un humain ou une machine. Je ne suis sûrement pas le seul à l'utiliser, et ça n'a sûrement pas grand chose d'extraordinaire, mais si jamais ça peut servir à d'autres personnes… (au moins à ceux à qui j'envoie mes corrections dans ce format ^^)
+ +Le plus simple est de partir d'un exemple. Considérons le texte suivant:
+Cec est un text de démonstratin. Comme vous pouvez aisément le constater il y a quelques lettres manquntes et quelqueslettres en troap ou des mauvaises lettres. C'est donc un bon exiample.+ +
Évidemment, le texte corrigé est:
+Ceci est un texte de démonstration. Comme vous pouvez le constater aisément il y a quelques lettres manquantes et quelques lettres en trop ou des mauvaises lettres. C'est donc un bon exemple.+ +
Pour ce texte, ma proposition de correction serait:
+Cec(+i) +text(+e) +démonstrati(+o)n +manqu(+a)ntes +quelques(+ )lettres +tro(-a)p +ex(-ia+e)mple+ +
Avec cette méthode, la correction est très courte, facilement lisible et très vite écrite. Détaillons-la un peu plus.
+ +Premier constat: il est très rare d'avoir des parenthèses au sein d'un mot. Et quand il y a des parenthèses, il n'y a jamais (en français correctement typographié, sauf erreur de ma part) un + ou un - qui suit une parenthèse ouvrante. On va donc englober dans des parenthèses nos corrections, directement au sein du mot. Au sein d'une parenthèse, on commencera toujours par le symbole - suivi de la lettre (ou des lettres consécutives) à retirer, s'il y a lieu. Puis viendra le symbole + suivi des lettres à insérer à la place dans le mot.
+ +Quand il manque une lettre dans le mot, elle est dans le champ de vision au sein de la parenthèse quand on lit le mot, et la lecture du mot est facilitée, tout en voyant immédiatement qu'il y a une faute à cet endroit. Quand il y a une lettre en trop, il suffit de ne pas lire la parenthèse pour avoir le mot complet bien écrit. Quand il y a eu une substitution, les lettres à insérer sont après le +, et les lettres à retirer sont après le -. La lecture d'un tel diff est donc très facile.
+ +Pour un ordinateur, il est également très facile de lire un tel diff. Le code serait le suivant:
+Une implémentation basique (et mal codée) en Python qui traite un mot serait :
+def inline_diff(word):
+ index = word.find('(-')
+ if index == -1:
+ index = word.find('(+')
+ if index == -1:
+ return word
+
+ index_end = word.find(')', index)
+ if index_end == -1:
+ return False
+
+ output = word[:index]
+ action = 'add'
+ for i in range(index, index_end):
+ if word[i] == '(':
+ continue
+ elif word[i] == '-':
+ action = 'remove'
+ elif word[i] == '+':
+ action = 'add'
+ else:
+ if action == 'remove':
+ continue
+ else:
+ output += word[i]
+ output += word[index_end+1:]
+ return inline_diff(output)Il reste à traiter le cas d'un diff complet. Plutôt que de fournir le texte complet, on peut se contenter de fournir une liste des corrections, comme la liste précédente, par ordre d'apparition dans le texte. Avec très peu de précautions nécessaires, une telle liste pourrait être traitée directement par un ordinateur pour apporter les corrections.
+ + +Mise à jour : Enfin, n'oublions pas d'aborder quelques limitations de ce système:
+Il existe des fois où la technique peut être utilisée moyennant quelques précautions. Dans cet exemple, les technique précédentes ne fonctionneront pas sans précautions.+Si on utilise technique(+s), c'est la première qui sera remplacée. Il faut donc étendre cette méthode pour traiter un contexte suffisant pour effectuer le remplacement sans ambiguïtés. Le diff adéquat serait: +
les technique(+s).
Dans ce texte, les sont mots inversés.+ Moyennant une implémentation un peu plus large de l'algorithme, on pourrait utiliser la méthode précédente comme ceci, pour corriger cette phrase: +
les (-sont) mots (+sont)+ car rien n'interdit à un mot d'être entièrement supprimé ou ajouté. +
EDIT : J'ai repris quelque peu le commentaire de FreshRSS, après discussion avec son auteur. J'avais raté certaines options en particulier.
+EDIT 2: Suite à quelques retours sur cet article, je tiens à préciser que la première partie de l'article (« Panorama de ce qui existe ») est volontairement courte et caricaturale. C'est une compilation caricaturale de réflexions que j'ai entendues, et je ne m'étends volontairement pas dessus, pour ne pas allourdir inutilement cet article qui vise d'abord à présenter les points qui me semblent importants pour mon lecteur de flux RSS idéal.
+Attention, cet article est un bon pavé et il est sûrement plein de répétitions… :)
+ +Sam&Max ont écrit récemment sur leur moteur idéal. Le moteur de blog est un réel problème, et j'adhérerais immédiatement à un moteur de blog qui satisfasse leurs critères (mais bon, pour l'instant ma solution maison patchée de partout fonctionne pas trop mal :). En revanche, un autre point mérite une bonne réflexion et pourrait être grandement amélioré et modernisé : le lecteur RSS.
+ +J'utilise actuellement Leed sur mon serveur. J'en suis globalement satisfait, mais certains points m'agacent et ne sont pas résolus, au fil des versions. Pourtant, après avoir fait le tour des solutions existantes, c'est la solution la plus fonctionnelle que j'ai trouvée… Je profite donc de ce billet pour dresser un bilan de ce que j'ai vu passer sur les lecteurs RSS et ce que je voudrais trouver dans mon lecteur RSS idéal.
+ +Tout d'abord, sebsauvage a fait il y a quelques temps un petit tour d'horizon des solutions de lecteurs RSS à héberger. Je vais faire court, au risque de m'attirer les critiques :
+Quoi que je fasse, je reviens vers Leed. De nombreuses fonctionnalités sont annoncées depuis un moment, et j'attends qu'elles voient le jour, mais il reste le plus fonctionnel et celui qui colle le mieux avec mon lecteur RSS idéal, tout en restant loin de la perfection. Le reste est moche, complexe, lent, et même les solutions payantes (mais opensources) ne s'en sortent guère mieux. Je n'utilisais pas Google Reader, mais s'il était dans la tradition des outils Google (simple, fonctionnel et rapide), je n'ai pas (encore ?) trouvé de réelle alternative.
+ +Concernant Leed, la première étape est bien sûr de changer le thème par défaut (Marigolds) pour un meilleur thème. Le plus complet et maintenu actuellement est Greeder de tmos (bien que Hot Beer se défende, même si je n'adhère absolument pas au format webzine). tmos travaille sur un pack Leed + greeder et sur l'intégration de Leed dans Yunohost, qui devrait lui redonner un peu de fraîcheur.
+ + +Je met à jour mon lecteur RSS toutes les heures, et j'y passe donc quasiment une fois par heure. Je ne veux pas passer dix minutes à chaque fois pour réussir à cliquer sur le bon bouton, ou pour attendre que la page soit chargée.
+ +Il faut donc qu'il soit beau, intuitif (pour ça, Leed + greeder remplit bien ce rôle), rapide et fonctionnel. Le but est aussi de lire des articles, pas de voir défiler des titres, donc il faut que les articles soient affichés en entier (mais personnalisables via une option pour satisfaire tout le monde), sans avoir besoin de cliquer trois fois sur chaque article pour le lire.
+ +Je le regarde de partout, et beaucoup sur mon portable, dans les transports. Or, bien souvent, il n'y a pas de réseau dans les transports, et je ne veux pas d'une énième app quand du HTML5 peut le faire. Du coup, un thème responsive, des actions tactiles (comme Greeder, en plus étendu) et une utilisation du local storage et le tour est joué :)
+ +Toutes ces fonctionnalités (et celles qui vont suivre) peuvent paraître en contradiction avec « être léger, rapide et fonctionnel », mais si le script est suffisamment compartimenté, on peut ne charger que ce qui sera utile à l'affichage et conserver un grand nombre de fonctionnalités avancées, sans alourdir nécessairement le script (sauf dans le cas où tout serait activé en même temps).
+ + +On ne peut pas faire un logiciel parfait, qui satisfasse tout le monde. Plutôt que d'opter pour le minimalisme et se priver ainsi de fonctions avancées, un système de plugins bien pensé me paraît mieux. Celui de Leed est bien pour ça, même s'il manque un peu de documentation. Idéalement, il faudrait même que les plugins et thèmes existants pour un des lecteurs RSS les plus répandu actuellement soient compatibles (mais là, je rêve je pense :).
+ +Quelques idées de plugins cools en vrac :
+Pour le côté user friendly et l'adoption par Mme Michu, il faudrait aussi une liste de plugins « officiels » (c'est-à-dire respectant les guidelines et donc compatibles) simple, à la wordpress. Il suffirait alors d'envoyer l'archive dans l'interface admin pour l'installer automatiquement.
+ +Idéalement, il faudrait des coding guidelines strictes, qui manquent sur les projets actuels. Notamment sur la façon d'écrire un thème ou sur les balises à utiliser dans un thème, afin de garantir la cohérence de l'interface et la rapidité du script. Leed par exemple, a un dépôt market très hétérogène, et des thèmes qui n'ont pas de base commune rendant très difficile l'implémentation de nouveau code sur plusieurs thèmes. Pire, certains plugins doivent être adaptés pour chaque thème, ce qui est une perte de temps considérable.
+ + +Une autre fonctionnalité qui me paraît importante est de pouvoir gérer finement les flux, c'est-à-dire pouvoir prioriser, classer, trier et filtrer des flux très facilement.
+ +Un premier point est la gestion des doublons. Très souvent, il arrive d'avoir des articles similaires, sur le même sujet, voire même des articles tout simplement identiques, si certains flux se recoupent. Le premier cas est difficile à trier et à filtrer (même si idéalement ces articles devraient pouvoir être regroupés ensemble), mais le deuxième est très simple à filtrer. Les doublons devraient donc être masqués et gérés comme un seul et même article.
+ +Un autre point important est la présence du multi-utilisateur. Cela permet ainsi de ne charger qu'une seule fois les liens communs à plusieurs comptes, et d'accélerer le rafraîchissement des liens ainsi que d'alléger la charge des serveurs. Je vois deux cas d'utilisation importants : pouvoir avoir une seule instance pour tout une famille, et pouvoir avoir différents comptes par activité (un compte pro et un compte perso par exemple).
+ +D'autres fonctionnalités sympathiques sont proposées par certains lecteurs RSS, notamment la gestion de la priorité des flux, pour prioriser certains flux.
+ +Je pense aussi qu'il y a moyen de faire des trucs très sympas avec les dossiers, qui sont bien trop rigides comme fonctionnement (et que je n'utilise pas personnellement). Sûrement un système de tags, ou un système flexible par mot-clé. Mais je n'ai pas encore d'idées précises à apporter pour cette réflexion. N'hésitez pas à partager les votres :)
+ + +Un des principaux avantages de s'auto-héberger est d'avoir les contraintes de transparence, de sécurité et de protection de la vie privée qu'on se fixe, au lieu d'être dépendant d'une solution tierce sur ces points.
+ +Un lecteur RSS idéal, et toujours dans l'optique de l'utilisation par le plus grand nombre, devrait :
+L'ergonomie est sûrement un des points faibles des lecteurs RSS disponibles actuellement (et du logiciel libre ?). Elle est bien souvent négligée, et cela prive bon nombre d'utilisateurs d'utiliser les scripts en question.
+ +Pourtant, il y a moyen de faire beaucoup de choses, notamment en usant (abusant ?) de JavaScript et des fonctionnalités récentes (transitions CSS, HTML5 etc). Du drag&drop s'implémente facilement, et facilite grandement l'utilisation pour beaucoup d'utilisateurs. Décrémenter un compteur d'éléments non lus en JavaScript chaque fois qu'on marque un élément comme lu prend 3 lignes de JavaScript et pourtant cela n'a été implémenté que récemment dans Greeder et dans le thème par défaut de Leed.
+ +De plus, j'ai besoin d'une application web pour ne pas dépendre de l'ordinateur (ou du téléphone) que j'utilise. Que je sois sur mon téléphone, mon ordinateur ou n'importe quel autre périphérique, je retrouve mes news dans le même état, sans synchronisation compliquée, et sans développer un logiciel différent par périphérique. Le web est vraiment magique pour ça. Mais ce n'est pas pour autant que je ne veux pas que cette webapp se rapproche le plus possible d'une application native (qui sont bien souvent des wrappers autour d'une interface web, sur mobile, de toutes façons). Ainsi, sur mon portable, je veux retrouver des actions tactiles, un stockage en local storage car je risque d'être déconnecté sans raison, et une interface utilisable pleinement sans jouer avec le zoom. Et sur mon ordinateur, je veux pouvoir bénéficier d'une navigation au clavier, avec des raccourcis claviers, et de fonctionnalités avancées telles que le rafraîchissment régulier ou la notification, afin de se rapprocher le plus possible d'une application (et peut être un jour tourner dans sa propre instance du navigateur, pour ressembler vraiment à une application ?).
+ +Côté interface, celle-ci doit faciliter la lecture en mettant l'accent sur le contenu et les actions importantes. Il y a aussi beaucoup de boutons qui ont une fonction peu claire dans les scripts que j'ai pu voir : double négation dans les questions qui nous fait répondre « oui » quand on voulait dire « non », pas de rappel du nom du dossier quand on veut marquer tout un dossier comme lu (ce qui nous fait nous demander si on a bien cliqué sur le bon bouton)… D'autre part, quand je qualifiais les interfaces de « moches » au début de cet article, c'était bien souvent que l'interface était peu claire / paumatoire / clicodrôme.
+ +La mode est au scroll infini. C'est bien pratique quand on a une connexion permanente, mais dès que la connexion coupe, qu'on recharge la page, et qu'on se retrouve tout en haut, c'est nettement moins drôle. Du coup, vive la pagination, en gardant une option pour le scroll infini, pour ceux qui l'aiment particulièrement. Par contre, si le local storage est très largement utilisé, le scroll infini peut s'envisager, car la perte de connexion ne bloquera pas la page.
+ +Enfin, un dernier point essentiel à mon avis est la possibilité de se connecter automatiquement et d'avoir un bookmarklet efficace pour ajouter des flux (idéalement, une intégration directe avec le module d'abonnement de Firefox :). Leed a un bon bookmarklet mais la connexion automatique n'est arrivée que récemment. Et attention sur ce point, Shaarli a une connexion automatique erratique, qui a tendance à ne pas passer chez certains hébergeurs.
+ + +Trop de scripts de ce genre ont aussi des traductions approximatives, monkey patchée ou bourrées de fautes. L'inernationalisation est importante de nos jours et ne doit pas être négligée, surtout qu'elle est désormais facilitée par les outils disponibles et qu'elle n'est pas si problématique si pensée depuis le début. Faire un test sur les nombres à afficher pour afficher l'accord si besoin n'est pas très long, et il est possible de faire une fonction à appeler pour le faire à chaque fois. Ce n'est pas grand chose, mais c'est plus propre, plus beau et plus tentant. Une bonne traduction, une bonne licence, un code en anglais et des coding guidelines motiveront plus les gens pour écrire du code et faire des contributions.
+ +Il faut aussi avoir une sortie régulière de versions, quitte à sortir des versions rapprochées. Si toutes les nouvelles fonctions sont regroupées dans une branche dev et regroupées dans une version stable une fois par an, Mme Michu ne verra qu'une version par an, et se dira donc que le développement est lent, même si chaque version apporte énormément de nouveautés. Au contraire, un dépôt avec des commits réguliers est plus attirant car on se dit que le logiciel vit, qu'il est suivi et qu'on n'aura donc pas à attendre longtemps si on rencontre un problème avec. Personnellement, si je rencontre un problème bloquant avec un logiciel et que celui-ci n'est pas résolu rapidement (en quelques semaines tout au plus), que je le veuile ou non, j'oublie l'existence de ce logiciel, je trouve des alternatives, et je retombe dessus par hasard quelques mois plus tard.
+ +De même, on ne peut pas tout développer, et on ne peut pas tout réinventer. Du coup, il devient important de virer les fonctionnalités inutiles, ou qui font doublon avec d'autres programmes, pour ne pas réinventer la roue et se consacrer sur les points essentiels pour le script.
+ + +Comme j'ai déjà insisté pas mal dessus, je reprendrais juste brièvement quelques points dans cette partie. Mais pour rester dans l'érgonomique et le beau, un tel script devrait être facile à installer, à configurer et à utiliser, par tous.
+ +Ceci passe par une interface user friendly, utilisant pleinement les fonctionnalités offertes par les navigateurs aujourd'hui (drag&drop, AJAX, …). Ceci passe aussi par l'internationalisation, la présence d'une vraie liste d'extensions, facilement utilisable, une doc claire et à jour et un fonctionnement identique (dans la mesure du possible) sur la plupart des hébergements disponibles.
+ +Du côté de la licence, un tel lecteur RSS devrait être sous une licence libre (dans le sens de logiciel libre), ce qui n'est malheureusement pas le cas de Leed aujourd'hui (sous licence CC-BY-NC-SA), qui a d'ailleurs une licence ambiguë, déconseilleé pour les codes sources (voir ici ou ici) et complexe comme le montre cet article chez Framasoft, un comble pour une licence qui se veut simple et intuitive. :)
+ +Enfin, un des principaux points est sûrement de pouvoir mettre à jour les flux facilement, sans y penser et sans intervention. Actuellement, la plupart des lecteurs nécessitent une intervention de l'utilisateur pour ajouter une crontask. C'est compliqué, source de problèmes, d'erreurs en recopiant etc, et ça complique l'installation pour pas mal de monde. Il y a sûrement moyen de rendre cela plus facile aussi, en tout cas ça serait top si c'était le cas. Owncloud par exemple propose de lancer les tâches par AJAX, webcron ou cron, sans configuration de la part de l'utilisateur.
+ + +Aucun lecteur RSS ne me satisfait pleinement, mais Leed me paraît le moins imparfait à l'heure actuelle. En prenant des briques à gauche, à droite, on réunit la plupart des fonctions qui me paraissent importantes, mais je pense qu'il y a encore moyen de faire beaucoup pour s'affranchir des modèles classiques et établis de lecteurs RSS et proposer quelque chose d'innovant, misant sur l'ergonomie et s'adressant au plus grand nombre.
+ +Je vais essayer de mettre ça en pratique, en gardant en tête les points que je juge le plus important : facilité d'utilisation, ergonomie, beau et performant. Je ferai sûrement quelques articles sur des points spécifiques que je croiserai. Si vous me lisez et que vous avez un hébergement mutualisé, n'hésitez pas à me donner des infos sur votre hébergement PHP (version de PHP, modules disponibles qui sont trouvables dans le phpinfo notamment) car je ne sais pas exactement quelles sont les installations typiques de PHP sur mutualisé.
+ +Enfin, beaucoup de fonctionnalités seraient implémentées très facilement en utilisant les technos à la mode, nodejs ou les solutions à base de python par exemple. Mais cela oblige à se priver du côté « facilement installable par tous » car ces solutions ne sont pas disponibles sur la plupart des hébergeurs mutualisés. Ça semble aussi être un des problèmes de Diaspora* par exemple, car j'entends régulièrement qu'installer son pod est compliqué, notamment car Diaspora* utilise Ruby, C'est vrai, et si c'est pour utiliser un pod public, proposé par la communauté, beaucoup d'utilisateurs ne voient pas de réelles différences par rapport à Facebook,
diff --git a/samples/libre_et_difficultes.html b/samples/libre_et_difficultes.html new file mode 100644 index 0000000..2c0d297 --- /dev/null +++ b/samples/libre_et_difficultes.html @@ -0,0 +1,25 @@ + +J'ai récemment vu passer cet article de slate.fr (Notre Mai-68 numérique est devenu un grille-pain fasciste) sur quelques shaarlis et cet autre article (Éloge funèbre d'un Internet libre et ouvert, par son assassin) sur le blog d'alias.
+ +Une phrase dans ce dernier article reprend une idée classique selon laquelle le libre n'est qu'un "truc de barbus", qu'il faut déjà faire partie des barbus pour utiliser un logiciel libre, étant donné l'attention portée à l'interface, etc.
+ +Mais je reste persuadé que, pour cela, il va falloir faire changer beaucoup de mentalités: d’une part, celle des utilisateurs, qu’ils prennent conscience du danger des systèmes fermés et centralisés, mais aussi des communautés hacker/open-source, qui doivent faire de gros efforts de simplification et de pédagogie pour faire des produits que même les plus technophobes voudront utiliser.+ +
Personnellement (et de toutes façons, ce billet ne sera qu'un avis personnel sur la question), je l'avoue, je n'aime pas développer d'interface. Je ne suis pas un fabuleux UI designer et une fois que j'ai un code fonctionnel, j'admet volontiers que j'ai tendance à m'en désintéresser, étant capable de l'utiliser et n'ayant pas le temps de développer plus le côté user-friendly. C'est certainement dommage, mais ce n'est pas ce qui m'intéresse... Mais ce n'est pas le cas de toute la communauté du libre, heureusement.
+ +Ainsi, on peut citer la fondation Mozilla qui a voulu (et a réussi à !) conquérir les Mme Michu avec son navigateur open-source : Firefox. De même, LibreOffice fonctionne très bien et est de plus en plus adopté par des gens qui ne sont pas technophiles du tout.
+ +En revanche, en s'engageant dans cette voie et en cherchant à séduire Mme Michu à tout prix, on court le risque de simplifier à l'extrême les développements, afin d'être à la portée de tous. On aboutit alors à une merveilleuse interface graphique à trois boutons, qui va certes séduire tout le monde, mais ne couvrira que 0.00(insérer autant de 0 que vous voulez ici)0001% du logiciel. On pensera notamment à toutes les surcouches à ffmpeg, qui ne vous apprennent en rien à utiliser ffmpeg, vous limitent les options disponibles plus qu'autre chose et surtout vous cache tout ce qui se passe en arrière-plan.Faut-il alors au contraire garder l'esthétique de la ligne de commande et former l'utilisateur à utiliser le logiciel, et à comprendre ce qu'il se passe en arrière-plan ? Pas sûr que ce ne soit une meilleure idée non plus...
+ +La question est également de savoir à quoi vise l'open-source. Le but est-il de fournir des logiciels adaptés aux end-users ? Vu le travail à fournir, cela voudrait dire diviser considérablement le nombre de scripts et de programmes. Ou alors faut-il garder cette multitude de logiciels et laisser les utilisateurs les plus doués techniquement trier et adapter ceux qu'ils jugent réellement nécessaires pour tout le monde ? De plus, un logiciel avec une interface graphique rudimentaire, voire en ligne de commande, laisse transparaître complètement ce qu'il se passe en arrière-plan. L'utilisateur a un contrôle total sur les actions du logiciel et peut appréhender l'ensemble des options.
+ +C'est à mon avis un des principaux intérêts de l'open-source : permettre aux utilisateurs de comprendre comment cela fonctionne et ce qu'il se passe derrière l'interface graphique. Alors certes, c'est rebutant et c'est dur au début, mais n'est-ce pas parfaitement réjouissant d'enfin comprendre comment fonctionne la machine ? J'ai personnellement plus appris en me débrouillant pour faire fonctionner des logiciels open-source (mais j'en ai également beaucoup abandonnés faute de documentation suffisante) qu'en cliquant sur un bouton pour avoir ce que je voulais (et la plupart des personnes qui découvrent la ligne de commande, qui commencent à programmer un peu, et qui comprennent alors réellement ce qu'est vraiment un "bug", dans mon entourage, me le confirme). Cliquer sur un bouton ne vous apprendra jamais à vous débrouiller seul, et ce n'est nullement rendre un service aux utilisateurs à mon avis. Cliquer sur un bouton pour que ça fonctionne, c'est pratique à 90% du temps, et ça permet d'aller plus vite sur certaines actions, mais ce n'est pas utiliser son ordinateur à mon avis, ce n'est qu'utiliser une infime partie des possibilités de l'ordinateur. (Et ne parlons même pas des cours d'"informatique" dans lesquels vous apprenez à utiliser Word... ce n'est pas de l'informatique...)
+ +Après, je ne suis pas d'accord sur le fait que la communauté open-source / hackers / geeks soit hermétique et fermée. Personnellement, je suis prêt à passer du temps à aider quiconque voudrait un coup de main, mais je ne veux pas le faire pour rien. Et le problème est sûrement plutôt de ce côté-là. Combien d'utilisateurs veulent "juste un système qui marche" ? Combien d'utilisateurs veulent mettre leur cerveau de côté et cliquer sur des bonbons rigolos et colorés dans un jeu bien connu sur un réseau social tout aussi connu plutôt que de comprendre ce qu'il se passe derrière ? Combien d'utilisateurs sont prêts à passer sous Linux en conchiant les idées et la philosophie associés ? J'avoue que dans ces situations, j'ai juste l'impression de me faire exploiter, et je n'ai aucune ambition d'ouvrir un service d'assistance informatique prochainement. Je pense que le problème est principalement à ce niveau, entre la différence de compréhension et d'appréhension de l'ordinateur par les différentes communautés, qui du coup, n'arrivent pas à échanger.
+ +Cf ce comic parfaitement illustratif :)
diff --git a/samples/nawel_shaarli.html b/samples/nawel_shaarli.html new file mode 100644 index 0000000..63cd0c2 --- /dev/null +++ b/samples/nawel_shaarli.html @@ -0,0 +1,17 @@ + +J'ai participé à l'iniative de Yome Papa Nawel des shaarlieurs et j'ai reçu mon cadeau aujourd'hui de Knah Tsaeb, après quelques déboires avec la Poste.
+ +Il m'a offert six humble bundle. Je connaissais de nom, mais je n'ai encore jamais expérimenté les humble bundle, ça sera l'occasion ! Merci beaucoup à toi, Knah Tsaeb !
+ +Du coup, j'en profite pour faire un petit article avec le déballage :)
+Avant :
+  +
+
Après :
+  +
+
Attention, article 3615MaLife. Pfiou, ça fait plus d'un mois que je n'ai rien posté… La faute à un mois de janvier très chargé. J'ai plusieurs articles en attente, mais je n'ai pas réussi à trouver le temps de les terminer…
+ +Dans tout ça, mon serveur vient d'être down pendant environ 24h. C'est aussi ça l'autohébergement, une galère qui vous tombe dessus et vous passez 24h sans votre serveur. En l'occurrence, mes partitions sont du LVM sur du LUKS pour mon serveur. Je dois donc rentrer une phrase de passe en me connectant en SSH au démarrage pour déverrouiller les disques. Ça a toujours bien marché, mais cela refusait de fonctionner depuis la dernière mise à jour que j'ai faite (qui aurait dû être anodine, soit dit en passant).
+ +N'ayant pas redémarré mon serveur depuis 122 jours avant, je ne savais pas exactement à quel moment ça avait pu se casser, et le fait de ne pas avoir d'accès physique au PC n'aide pas à débugger. Enfin, finalement, j'ai réussi à tout redémarrer, par je ne sais trop quel moyen, et je prie pour que ça fonctionne encore la prochaine fois…
diff --git a/samples/notif_weechat_urxvt.html b/samples/notif_weechat_urxvt.html new file mode 100644 index 0000000..7847294 --- /dev/null +++ b/samples/notif_weechat_urxvt.html @@ -0,0 +1,26 @@ + +After moving from irssi to weechat, I decided to look for a way to have local notifications for IRC messages. The problem is that I run weechat through a screen on my server, which I access thanks to SSH. Thus, I need to find a way to allow weechat to communicate to my local terminal and send notifications.
+ +I found many solutions on the web which were using a local server or a pipe file. But these aren't fitted to my needs, as they need an external program running on my machine, which I don't want. I was quite sure there could be a way to do it, with nothing more than my terminal emulator and weechat plugins, and I finally found it. My solution is based on karma-lab's one [French].
+ +The idea is to use the Bell signal which corresponds to the ASCII escape sequence 7 to raise attention (beep signal). The following steps work fine with UrXVT and weechat in a screen session. It may be possible to adapt this to other terminal emulators or terminal multiplexers (such as tmux) but I don't use them and can't help you much with it. We will define our own escape sequence, that will be interpreted by an UrXVT plugin and will spawn a notification with the IRC message.
+ +First of all, you will have to modify your ~/.Xdefaults or your ~/.Xresources to tell UrXVT to listen for bell signals. In order to do so, just add the following line:
+URxvt*urgentOnBell: true+
Then, reload it:
+$ xrdb -load ~/.Xdefaults+ +
Your UrXVT terminal now listens to bell signals. But we'd like them to spawn real local notifications. For this, I used libnotify, which is built-in in gnome. The main idea is to enhance our bell signal with a more complete escape sequence to include a message to display (using the so-called osc sequences). Thus, the sequence sent to UrXVT will look like [ESC]777;notify;TITRE;MESSAGEBELL]. Just add the following plugin (written by Karma-lab[French] and slightly modified by me to enhance security) to your UrXVT and you are ready to go. So, you should put this plugin in /usr/lib/urxvt/perl/notify.
+ +To test that everything worked correctly, you can use the following command:
+$ echo -ne "\033]777;notify;Moi;Hello World\007\007"+
which should spawn an "Hello World" notification on your desktop.
+ +Finally, if the previous example is working fine, let's integrate it to Weechat. We'll need another plugin for weechat, to make him write this escape sequence when needed to send notifications. This plugin is also from karma-labs, but as my weechat is running in a screen session, I had to tweak it a bit. I improved security of the plugin as well, to prevent any unauthorized code execution. Concerning screen, it is “consuming” the escape sequences for itself, and you have to tweak it a bit to make it pass through screen. The python script to load in your Weechat can be found here.
+ +Have fun with IRC and your brand new notifications !
diff --git a/samples/notification_sms_free.md b/samples/notification_sms_free.md new file mode 100644 index 0000000..48476bd --- /dev/null +++ b/samples/notification_sms_free.md @@ -0,0 +1,29 @@ + + +*Edit* : Cela fait bientôt une semaine que l'API Free me renvoie un 402, en boucle… je ne peux plus envoyer de SMS depuis l'API. Je ne sais pas combien de temps ça va durer, à suivre… mais du coup c'était pas forcément une super idée… soyez prévenus ! :) + +Si vous êtes client Free Mobile (forfait à 2€ ou à 19€), sachez que Free met à disposition gratuitement une [API d'envoi de SMS](http://www.freenews.fr/spip.php?article14817). _Via_ un appel HTTP, vous pourrez désormais vous envoyer des notifications par SMS (uniquement à destination de votre numéro donc), ce qui fait le plus grand bonheur des utilisateurs de solutions domotiques. + +Dans cet article, je vais l'utiliser dans un but différent : recevoir mes emails par SMS. Je pars d'ici peu pour une semaine à l'étranger (pas de connexion internet…) et ai besoin de relever mes emails régulièrement. Grâce à ce service, je vais pouvoir les recevoir par SMS. + +_Note_ : Recevoir ses emails par SMS peut poser des problèmes de vie privée, votre opérateur voyant passer tous vos SMS notamment. Ça peut être d'autant plus gênant si vous recevez des rappels de mot de passe par email, qui vous seront transmis par SMS. + +Je me suis grandement inspiré de [cet article](http://louis.jachiet.com/blog/?p=228) mais ai réécrit le script. Le script ci-dessous est donc en Python (que je maîtrise mieux que Perl), gère plusieurs serveurs et se connecte en IMAP à vos boîtes, pour pouvoir récupérer des emails chez Gmail and cie, pour lesquels on ne peut pas mettre de règles `procmail`. Dans mon script, les identifiants / mots de passe sont en clair pour pouvoir l'éxecuter _via_ une `crontask`. Si vous ne contrôlez pas le serveur sur lequel vous faites tourner ce script ou ne réglez pas correctement les permissions, attention à vos mots de passe ! + + +Première étape, il faut aller activer l'option sur votre compte. Sur le site de Free, Gérer mon compte → Mes Options → Notifications par SMS → Activer. Vous pourrez alors récupérer votre clé d'API. + +Deuxième étape, récupérer [ce script](https://github.com/Phyks/Emails_SMS_Free_Mobile_API) qui va vous permettre de vous connecter à vos boîtes IMAP. + +Troisième étape, éditer le script pour correspondre à vos besoins. Tous les paramètres à modifier sont entre des commentaires `# EDIT BELOW ACCORDING TO YOUR NEEDS` et `# YOU SHOULD NOT HAVE TO EDIT BELOW`. Il vous faudra ajouter vos serveurs IMAP (serveur, login et mot de passe, et boîte à utiliser (par-défaut, INBOX)). Vous pouvez ajouter autant de serveurs que vous voulez en dupliquant les dictionnaires au sein de la liste `imap_servers`. Il vous faudra également éditer votre login pour l'API (`IDENT`, identifiant de connexion au compte) et la clé d'API à utiliser (`PASS`). + +_Note_: L'URL ne devrait pas avoir besoin d'être modifiée, et `save_path` est le fichier JSON utilisé pour stocker les identifiants des emails relevés (et uniquement les identifiants), pour ne pas renvoyer la même notification plusieurs fois. + +Finalement, il ne reste plus qu'à mettre ce script sur un de vos serveurs (ou une machine allumée suffisamment souvent), et à le lancer _via_ une `crontask`, par exemple `*/15 * * * * python3 ./mails_sms_free.py > .mails_sms_free.log` pour relever vos emails toutes les 15 minutes. + +_Note_ : J'utilise ce script depuis une journée sans problèmes, mais il est sûrement imparfait. N'hésitez pas à [me signaler](https://phyks.me/contact.html) (ou _via_ les _issues_ Github) d'éventuels problèmes rencontrés. diff --git a/samples/out.html b/samples/out.html new file mode 100644 index 0000000..7816f79 --- /dev/null +++ b/samples/out.html @@ -0,0 +1,11 @@ + +Je vais changer mon serveur kimsufi que j'ai depuis 1 an, pour un nouveau de la gamme 2013, largement plus puissant pour le même prix. Du coup, je vais tout transférer sur la nouvelle machine (mufasa.phyks.me) dans les prochains jours, et, me connaissant, je vais sûrement rater un truc :)
+ +Du coup, il se peut que vous rencontriez quelques difficultés à accéder à mon site dans les prochains jours. J'éditerai cet article quand tout sera migré.
+ +Update (13/04, 17h33) : Migration terminée. Tout s'est bien passé en fait, et je ne crois pas avoir eu d'interruption de service (à part git.phyks.me pendant quelques heures).
diff --git a/samples/pourquoi_gpl_pas_libre.html b/samples/pourquoi_gpl_pas_libre.html new file mode 100644 index 0000000..64009f8 --- /dev/null +++ b/samples/pourquoi_gpl_pas_libre.html @@ -0,0 +1,69 @@ + +Cet article est une traduction (dont je ne garantis pas la qualité :) de cet article (en anglais). Je n'ai pas réussi à contacter l'auteur, et si celui-ci passe par là et souhaite le retrait de la traduction, je la retirerai.
+ +Cet article résume bien le problème que me pose la clause de redistribution sous une licence compatible, qui complique bien souvent l'utilisation de la licence (notamment car ce qu'on peut réellement faire avec un code sous GPL n'est pas toujours très clair et intuitif). C'est une des raisons pour laquelle je privilégie généralement une licence plus permissive, comme la MIT. La dernière partie sur l'échec de la GPL est moins convaincante, et peut être même un peu tirée par les cheveux, mais elle fait partie de l'article donc je la laisse.
+ +À partir de maintenant et dans toute la suite, « je » désigne donc l'auteur de l'article précédent.
+ +La Free Software Foundation (FSF) présente la GPL comme un défenseur idéal de vos libertés. On nous dit que la GPL est au cœur de la défense de quatre libertés :
+« Qu'est-ce que le logiciel libre ? », sur le site de la GNU
+ +J'affirme cependant que la GPL ne nous donne pas de liberté, mais juste différentes restrictions. J'affirme de plus qu'elle ne nous donne pas toutes les libertés précédentes. Dans cet article, je défend que la GPL est intrinsèquement imparfaite quand il s'agit de libérer les logiciels.
+ + +Permettez moi d'ouvrir une parenthèse avant de commencer. Je voudrais présenter un sujet lié qui est au cœur de mon argumentation, et qui est la question de savoir combien de code exactement vous avez écrit. Imaginons un scénario typique : vous êtes l'auteur d'une bibliothèque libre et open source. Le but de cette bibliothèque n'importe pas particulièrement, donc disons qu'elle sert à chiffrer des widgets. Vous mettez tout votre talent dans cette bibliothèque, et elle devient stable et très complète. Le diagramme représente le projet à ce moment :
+ +
+Vous êtes fier de votre projet.
Supposons donc maintennt qu'une tierce partie prenne votre code et construise quelque chose par dessus. On pourrait le représenter comme ceci :
+ +
+Un important et un petit ajout à votre projet.
Ce qui est important ici, c'est de réaliser que la quantité de code que vous avez écrite ne change pas. Même si l'ajout de la tierce partie consiste seulement en une jolie interface graphique pour votre bibliothèque, la quantité de code que vous avez écrite n'a pas augmenté, ni diminué.
+ + +Ok, posons donc maintenant la question : quelle est la pertinence de tout ceci ? Ça nous a aidé à clarifier ce que vous couvrez exactement par la licence lorsque vous appliquez une licence GPL à votre code. Vous couvrez votre code, et seulement votre code. Et pourtant, la GPL restreint la licence des travaux dérivés. Notons ici que les travaux dérivés sont intégralement le travail de quelqu'un d'autre.
+ +L'argument le plus courant que j'ai entendu pour favoriser la GPL est qu'avec une licence plus faible (disons BSD), une tierce partie peut prendre votre code, l'étendre, et fermer l'accès aux sources. Réfléchissons donc à ce que cela signifie. Pour fermer l'accès à votre code, ils auraient du le prendre, retirer toutes les sources en accès libre pour ce code, et ensuite le distribuer à nouveau en closed source. Mais cela n'a aucun sens. Vous distribuez toujours votre code source sous une licence libre et open source, donc en quoi l'ont-ils rendu closed source ? Ils ne l'ont pas fait : votre code est toujours open source. Donc, qu'ont-ils rendu closed source ? Et bien, la réponse est « leur code », et seulement leur code est closed source, et c'est très bien : ils sont dans leur droit d'appliquer la licence de leur choix à leur code.
+ +Donc la conclusion est qu'une entreprise peut venir, prendre libWidgetCrypt et proposer un petit wrapper autour, et commencer à faire d'énormes profits en vendant le résultat $10,000. Oui, c'est possible, mais c'est aussi un scénario assez improbable. Si tout ce qu'ils ont fait a été d'écrire un petit wrapper, alors vous, ou quelqu'un d'autre dans la communauté open source est parfaitement capable de réaliser un tel wrapper en un rien de temps. Et alors, tout ce qu'il vous reste à faire est de casser les prix et d'ajouter un bon gros morceau de liberté.
+ +Le scénario le plus probable, cependant, est qu'une entreprise arrive, prenne libWidgetCrypt et produise un gros morceau de code supplémentaire, qui utilise juste votre bibliothèque dans sa base. Alors, cette entreprise va vendre son code, et ses extensions pour un montant élevé, et ils ont parfaitement le droit de le faire. Après tout, c'est leur code.
+ +Croyez le ou non, ce scénario est encore un scénario bénéfique pour vous. Cette entreprise est susceptible de trouver des bugs dans libWidgetCrypt, et de les corriger. De mon expérience de ce genre de choses, ils contribuent et vous font parvenir leurs correctifs plus souvent qu'on le pense, même si rien ne les y oblige ! Oui, il arrive qu'ils corrigent la bibliothèque et s'enfuient avec les correctifs, mais encore une fois, ils ont écrit les correctifs, ils ont le droit de le faire !
+ + +Je suis entré dans beaucoup de détails sur ce que vous mettez sous GPL quand vous appliquez une licence GPL à votre code, mais je n'ai pas encore parlé de ce que j'avais annoncé au début de cet article. Je ne vous ai pas dit pourquoi la GPL n'est pas une licence libre. Pour cela, je vais me concentrer sur la dernière liberté qu'elle affirme offrir : « La liberté d'améliorer le programme, et de diffuser les améliorations (et les versions modifiées en général) au public, pour que la communauté entière en bénéficie (liberté 3). ». Supposons que j'ai une entreprise, et que je crée un produit à distribuer. J'aimerais utiliser votre bibliothèque dans mon programme, j'aimerais même améliorer votre bibliothèque, et diffuser les améliorations publiquement, pour que l'intégralité de la communauté en bénéficie. Malheureusement, je dois finir par vendre un produit, donc j'aimerais garder le cœur de mon projet closed source. Malheureusement, la GPL proscrit ce genre de choses.
+ +Nous avons donc un bon citoyen, une entreprise qui veut diffuser leurs correctifs à la bibliothèque, et pourtant la GPL leur interdit de le faire. Elle ne leur donne aucune liberté ! À la place, la GPL est un ensemble de restrictions.
+ +Il se peut que vous trouviez que l'ensemble de restrictions que la GPL offre est plus moralement acceptable que les licences closed source traditionnelles, mais ce n'est pas une licence libre. Elle ne donne pas de liberté, elle donne différentes restrictions.
+ + +La GPL n'est pas une licence libre, en ce qu'elle restreint les libertés aux seules personnes qu'elle juge moralement acceptables. Il y a souvent des gens qui ne tombent pas dans cette case « moralement acceptable », mais qui ont pourtant de très bonnes intentions. La GPL est donc trop restrictive pour beaucoup de projets. À la place, c'est souvent une bonne idée d'utiliser une véritable licence FOSS, comme la licence BSD par exemple. En faisant cela, vous ne vous rendrez pas vulnérable pour des entreprises qui voudraient passer magiquement votre code en closed source, car vous continuerez à le distribuer. Il se peut qu'ils passent en closed source un petit ajout à votre code et essayent de le vendre pour des sommes astronomiques. Cependant, dans ce cas, vous pouvez aussi reproduire le même changement mineur, et le donner entièrement librement à la communauté.
diff --git a/samples/pulseaudio_remote.md b/samples/pulseaudio_remote.md new file mode 100644 index 0000000..6cba65e --- /dev/null +++ b/samples/pulseaudio_remote.md @@ -0,0 +1,37 @@ + + +J'ai un PC fixe et un portable, et je cherchais un moyen de balancer le son de mon portable sur les hauts-parleurs de bonne qualité branchés sur mon PC fixe, quand je suis sur le même réseau. Et en fait, c'est très simple à faire avec PulseAudio. + + +## La première méthode, simple, qui marche partout + +S'assurer d'avoir `pulseaudio` configuré sur ses ordinateurs, et installer `paprefs`. Lancer `paprefs` et dans l'onglet `Multicast/RTP`, cocher la case _receiver_ sur le PC sur lequel les hauts-parleurs sont branchés, et la case _sender_ sur l'autre. + +Sur le PC qui envoie la musique (_sender_), vous avez le choix entre trois options, dont seulement deux nous intéressent : `Send audio from local speakers` (qui enverra tout le son local sur les hauts-parleurs distants) et `Create separate audio device for Multicast/RTP` (qui vous rajoutera une sortie son `Multicast/RTP` que vous pourrez utiliser ou non, par application). + +Si vous n'avez pas de pare-feu et que vous êtes bien sur le même réseau, c'est tout ce que vous avez à faire ! + +Par contre, vous remarquerez vite que la qualité n'est pas top (au moins chez moi) : un bon FLAC d'un côté ressort vite comme un MP3 64k d'il y a quelques années de l'autre côté… + + +## La deuxième solution, encore plus simple, qui marche mieux ! + +La deuxième solution consiste à utiliser les deux premiers onglets de `paprefs` : `Network Access` et `Network Server`. + +Sur le PC qui envoie le son, cochez la case `Make discoverable PulseAudio network sound devices available locally` dans le premier onglet. + +Sur le PC qui reçoit le son, cochez les trois premières cases (`Activer l'accès réseau aux périphériques de son locaux`). + +Et c'est tout =) Vous aurez désormais les sorties audio de votre autre PC qui apparaîtront chez vous (par exemple dans `Audio -> Périphérique audio` dans VLC). Et pour le coup, plus aucun problème de qualité à signaler ! Testé en filaire, et aucun problème de débit / lag / son à signaler pour l'instant. + +À noter cependant que chez moi, j'ai deux sorties qui sont disponibles, une appelée `Audio interne…` et l'autre appelée `Simultaneous output to Audio interne…`. Si j'utilise la deuxième, j'ai le son qui saute, et c'est inutilisable, mais la première fonctionne nickel. + + +## Références + +Principalement un seul lien : [http://www.freedesktop.org/wiki/Software/PulseAudio/Documentation/User/Network/#index2h3](http://www.freedesktop.org/wiki/Software/PulseAudio/Documentation/User/Network/#index2h3). Mais ils font tout à coup de ligne de commande et c'est en fait bien plus simple de passer par paprefs. diff --git a/samples/sortez_vos_emails.md b/samples/sortez_vos_emails.md new file mode 100644 index 0000000..2d98b23 --- /dev/null +++ b/samples/sortez_vos_emails.md @@ -0,0 +1,30 @@ + +*TLDR in English* : If you care about your scripts, if you love them and want them to be used, to live, *leave* a simple way to contact you (a.k.a. an email address which has always been working, works and will be always working, because email protocol is an [Internet Standard](https://en.wikipedia.org/wiki/Internet_Standard)). I'm fed up with trying to find you and spend an incredible amount of time doing so… + +Je vois de plus en plus de gens qui font un script, souvent fort utile, et qui le balancent dans un coin, sur Github, sur Sourceforge ou autre. Problème : ils ne laissent aucun moyen décent de les contacter (un email quoi !). Du coup, très souvent : + +* On veut réutiliser le script mais il n'y a pas de licence… Tant pis, il n'y a plus *aucun* moyen de contacter l'auteur. + +* Il y a une faille très grave dans le code, qu'on ne veut pas diffuser dans les _issues_ Github pour ne pas la rendre directement publique, tant pis, il n'y a pas moyen… Ça sera public ou rien (et encore, quelques fois c'est rien du tout car les _issues_ ne sont pas activées…) + +* Ou alors l'auteur laisse un pseudo, un lien vers un site web, une liste de "comptes en ligne"… mais aucun email. Je n'ai *pas* de compte Twitter, je n'ai *pas* de compte Facebook/Hangout whatever, j'ai depuis peu un compte Diaspora*, mais un email, tout le monde peut l'utiliser, l'utilise depuis 30 ans, et l'utilisera sûrement dans 30 ans. C'est tellement plus simple… mais non, on liste tous ses comptes sur les rezosocios. + +Du coup, j'en ai marre de courir derrière les gens, à essayer de croiser des comptes jusqu'à avoir une adresse email, qui bien souvent n'est plus utilisée. Sur les derniers scripts que j'ai réutilisé, 9 fois sur 10, ça s'est passé comme ceci : + +* Je trouve un script sur Github, sans licence… J'ai besoin de le réutiliser, et j'ai la flemme de le réécrire. Je cherche un contact. +* J'atterris sur le profil Github de l'auteur, aucune adresse email, rien… Je n'ai que le pseudo et les autres projets de l'auteur (qui bien souvent sont inexistants en fait). +* Je cherche surI was looking for a way to add custom vim options on a per-repo basis. The standard way I saw for now, was adding some comments to change the Vim config on a per-file basis. There were some alternatives which were working for any project folder (and not only git repos) but they were only working if you start Vim from the root of the project, or they were exploring the tree from local folder up to root (and needed a plugin). None of them were satisfactory.
+ +When I edit a file and need specific Vim configuration, it is usually inside a git repo. So, it is easy to know what is the root folder, and I just wanted to search for a Vimrc file in this folder. No complicated tree searching, working from anywhere inside the repo, no per-file specific configuration.
+ +First of all, the magic command I used to find the git root folder is git rev-parse --show-top-level.
+ +Then, all I had to do is wrap it correctly in my .vimrc:
+
+" Git specific configuration
+let git_path = system("git rev-parse --show-toplevel 2>/dev/null")
+let git_vimrc = substitute(git_path, '\n', '', '') . "/.vimrc"
+if !empty(glob(git_vimrc))
+ exec ":source " . git_vimrc
+endif
+
+
+
+This small code, added at the end of your .vimrc will just look for a .vimrc at the root the git repository and source it if possible. That's exactly what I wanted :)
diff --git a/samples/synchronisation_backups_1.md b/samples/synchronisation_backups_1.md new file mode 100644 index 0000000..18f6a9a --- /dev/null +++ b/samples/synchronisation_backups_1.md @@ -0,0 +1,96 @@ + +## Étude des solutions disponibles + +J'utilise quotidiennement au moins 2 ordinateurs : mon ordinateur portable et mon fixe. Tous les deux ont des gros disques durs (> 1 To) et je cherche depuis quelques temps à les synchroniser pour les utiliser de façon totalement transparente avec mes fichiers (et avec la configuration utilisateur de base, tel que mon `.vimrc`, mon thème pour `rxvt-unicode`, etc.). + +J'ai également un gros disque dur externe, sur lequel je veux faire des _backups_ complets réguliers de certains fichiers. + +Je dois donc maintenir en permanence 3 disques durs synchronisés : celui de mon ordinateur fixe, de mon portable et mon disque dur externe. Faire ça à la main, c'est très long et fastidieux (et potentiellement compliqué). Je cherche donc un moyen d'automatiser tout ça proprement. De plus, j'ai un serveur dédié, avec de l'espace disque disponible, sur lequel je voudrais stocker une partie des sauvegardes, pour avoir un _backup_ décentralisé en cas de pépin. + +Les solutions à envisager doivent répondre aux critères suivants : + +* Pouvoir facilement choisir les dossiers et les fichiers à synchroniser et être capable de synchroniser de gros fichiers sans problèmes et dans des temps décents. Je veux synchroniser tout mon _home_ entre mes deux ordinateurs et mon disque dur externe, mais je ne veux pas synchroniser toutes mes musiques et vidéos avec mon serveur, pour ne pas le saturer inutilement. J'ai pas mal de scripts déjà versionnés par Git également, que je veux pouvoir exclure facilement. +* Proposer une solution de sauvegarde chiffrée (transferts chiffrés entre les postes et chiffrement de mes données sur mes serveurs). +* Permettre une architecture décentralisée, pas besoin de repasser par mon serveur pour synchroniser mes postes quand ils sont sur le même réseau local. + + +J'ai également repéré trois solutions potentielles : [Unison](http://www.cis.upenn.edu/~bcpierce/unison/), [Syncthing](http://syncthing.net/) trouvé grâce à [cet article de tmos](http://tomcanac.com/blog/2014/07/14/syncthing-alternative-libre-btsync/) et [git-annex](http://git-annex.branchable.com/) trouvé par [cet article](http://flo.fourcot.fr/index.php?post/2013/07/19/J-ai-d%C3%A9couvert-git-annex). (Je cherche bien sûr une solution _opensource_ à installer sur mon serveur) + + +### Unison + +[Unison](http://www.cis.upenn.edu/~bcpierce/unison/) est un programme de synchronisation de fichier multiplateforme, écrit en Ocaml. Il gère les conflits automatiquement si possible, et avec intervention de l'utilisateur si besoin. Il prend un grand soin à laisser les systèmes en état fonctionnel à chaque instant, pour pouvoir récupérer facilement en cas de problèmes. Par contre, le projet était un projet de recherche initialement, et avait donc un développement très actif. Ce n'est plus le cas, et le développement est beaucoup moins actif, comme expliqué [sur la page du projet](http://www.seas.upenn.edu/~bcpierce/unison//status.html). + +Autre limitation : il n'est possible de synchroniser que des *paires* de machines avec Unison. Cela veut dire que pour synchroniser mes 3 machines, je vais devoir utiliser une configuration en étoiles, en passant forcément par mon serveur. C'est pas top car mon portable et mon ordinateur fixe étant très souvent sur le même réseau, il peut être intéressant de s'affranchir du serveur dans ce cas, pour avoir des taux de transfert plus élevés. + +Enfin, il semble assez non trivial d'avoir un chiffrement des données synchronisées, et ce n'est pas implémenté directement par Unison. Il faut donc rajouter une couche d'Encfs ou autre. [Une discussion sur le forum archlinux](https://bbs.archlinux.org/viewtopic.php?pid=1317177#p1317177) (en anglais) évoque cette possibilité, et [un post](http://www.mail-archive.com/encfs-users@lists.sourceforge.net/msg00164.html) sur la mailing-list [Encfs-users] donne quelques détails supplémentaires. + + +### Syncthing + +(Je reprends les informations du [site officiel](http://syncthing.net/) et de [l'article de Tom](http://tomcanac.com/blog/2014/07/14/syncthing-alternative-libre-btsync/).) + +Syncthing est écrit en Go. Toutes les communications sont chiffrées par TLS et chaque nœud est authentifié et doit être explicitement ajouté pour pouvoir accéder aux fichiers. Syncthing utilise donc son propre protocole, et sa propre authentification. Il est multiplateforme, a une très jolie interface et ne requiert aucune configuration particulière (il est censé fonctionner _out of the box_, en utilisant uPnP si besoin pour ne pas avoir besoin de mettre en place de translation de port). + +Chaque machine peut échanger avec toutes les machines avec lesquelles il y a eu un échange d'identifiants. On peut donc très facilement choisir de construire une architecture centralisée ou décentralisée (dans le premier cas, toutes les machines n'auront que l'identifiant du serveur central, dans le deuxième cas toutes les machines auront les identifiants de toutes les autres). + +Toute la configuration se fait par une jolie interface web, protégée par mot de passe. Vous pouvez partager chaque dossier comme bon vous semble, et vous pouvez même partager certains dossiers avec des personnes extérieures, à la dropbox, sans dropbox :). Et de par l'architecture du logiciel, il n'y a pas de _serveur_ ni de _client_ mais un seul logiciel qui tourne partout. + + + +Le code est disponible sur [Github](https://github.com/syncthing/syncthing), le dépôt est actif et les tags sont signés. + +Il satisfait donc a priori la plupart de mes besoins. Il faut juste que je trouve un moyen de chiffrer mes documents sur mon serveur (mes disques sont déjà chiffrés, mais je voudrais avoir un gros conteneur déchiffré à chaque synchronisation, et verrouillé après idéalement). Apparemment, c'est [en cours de discussion](https://github.com/syncthing/syncthing/issues/109). + +Concernant la gestion des conflits, elle n'a pas l'air parfaite, comme le montre [cette _issue_](https://github.com/syncthing/syncthing/issues/220) sur Github. Il semblerait que la politique actuelle soit _newest wins_ ce qui peut causer des pertes de données (une copie de sauvegarde est peut être réalisée, car SyncThing peut versionner les fichiers, mais je ne suis pas sûr de ce point, à tester). + + +### Git-annex + +[Git-annex](http://git-annex.branchable.com/) est un programme permettant de synchroniser ses fichiers en utilisant Git. En fait, il est vu comme un plugin pour Git, et il va stocker les fichiers dans un dépôt Git, mais ne pas versionner leur contenu. Du coup, on évite de devoir versionner des gros fichiers et donc les problèmes habituels de Git avec des gros fichiers potentiellement binaires. + +C'est certainement le programme le plus abouti des trois présentés ici, son développement est actif, il y a une communauté derrière (et du monde sur IRC !) et le développeur a réussi une campagne Kickstarter l'an dernier pour se financer pour travailler sur le logiciel pendant un an. Il a notamment implémenté un assistant web dernièrement, permettant de gérer ses synchronisations _via_ une interface web fort jolie à la Syncthing, en s'affranchissant de la ligne de commande. Je pense quand même que Syncthing est plus _user friendly_. + +Les possibilités du logiciel, listées sur [la page du projet](http://git-annex.branchable.com) sont assez impressionnantes. Parmi les fonctionnalités avancées : + +* Possibilité d'avoir tous les fichiers listés partout, même si leur contenu n'est pas effectivement présent sur le disque. Du coup, git-annex sait où aller chercher chaque fichier pour nous aider à nous y retrouver avec plusieurs supports de stockage (plusieurs disques durs externes de _backup_ par exemple) + +* Git-annex utilise des dépôts standards, ce qui permet d'avoir un dépôt toujours utilisable, même si Git et Git-annex tombent dans l'oubli. + +* Il peut gérer autant de clones qu'on veut, et peut donc servir à synchroniser selon l'architecture qu'on veut. Il est capable d'attribuer des poids différents à chaque source, ce qui veut dire que je peux synchroniser mes ordinateurs _via_ mon serveur, et si jamais ils sont sur le même réseau local, je peux synchroniser directement sans passer par mon serveur. + +* Il gère plusieurs possibilités de chiffrement, pour chiffrer les copies distantes, sur mon serveur par exemple. Et il permet de chiffrer tout en partageant entre plusieurs utilisateurs. Il peut utiliser d'office un serveur distant tel qu'un serveur sur lequel on a un accès SSH (et les transferts sont immédiatement chiffrés par SSH du coup) ou encore un serveur Amazon S3. + +* Possibilité de partager des fichiers avec des amis en utilisant un serveur tampon. Ce serveur stocke uniquement les fichiers en cours de transfert et n'a donc pas besoin d'un espace disque considérable. + +* Il gère les conflits. + +* Il peut utiliser des _patterns_ pour exclure des fichiers, ou les inclure au contraire. On peut faire des requêtes complètes telles que "que les MP3 et les fichiers de moins de N Mo". + +* Bonus : il peut être utilisé pour servir un dossier semblable à mon [pub.phyks.me](http://pub.phyks.me), que j'implémenterai sûrement du coup, pour permettre de cloner tout mon `pub` directement. + +Plusieurs _screencasts_ sont disponibles dans la [documentation](http://git-annex.branchable.com/assistant/) et un retour en français est disponible [ici](http://flo.fourcot.fr/index.php?post/2013/07/19/J-ai-d%C3%A9couvert-git-annex). + +Ses points forts ont vraiment l'air d'être ses fonctions avancées et la possibilité de gérer finement la localisation des fichiers. Git-annex ne se contente pas de vous permettre de synchroniser des fichiers, mais aussi de les déplacer géographiquement, partager et sauvegarder. + + + +## Conclusion (temporaire) + +J'ai repéré trois solutions envisageables pour l'instant : Unison, SyncThing et git-annex, par ordre de fonctionnalités. Les informations précédentes sont uniquement issues des articles, documentations et retours d'utilisateurs. SyncThing a l'air le plus _user friendly_ de tous, et il a des fonctionnalités intéressantes et avancées. git-annex est clairement celui qui a le plus de fonctionnalités, mais il est donc également plus compliqué à prendre en main. + +Après cette analyse, je pense donc partir sur git-annex pour mettre en place mes sauvegardes. Rendez-vous bientôt pour la deuxième partie de cet article, avec un retour complet sur ma procédure de synchronisation (dans quelques temps quand même… faut que je réfléchisse à mon truc et que je dompte git-annex =). + + +## Notes + +* Après réflexion, utiliser le disque dur externe en plus fait beaucoup de redondance. Du coup, si je ne peux synchroniser qu'une partie de mes fichiers sur celui-ci, c'est encore mieux (par exemple que ma bibliothèque de musiques / films). + +* Une autre solution qui pourrait vous intéresser est [Tahoe-LAFS](https://tahoe-lafs.org/trac/tahoe-lafs) qui distribue vos fichiers sur plusieurs serveurs de sorte qu'aucun serveur ne puisse connaître vos données, et que si un serveur est en panne, vous puissiez toujours les récupérer (par défaut il utilise 10 nœuds pour le stockage et ne nécessite que 3 nœuds pour reconstituer les données, si j'ai bien compris). Voir aussi [cette vidéo sur rozoFS](http://numaparis.ubicast.tv/videos/rozofs/) à PSES 2014, pour avoir une idée de comment cela fonctionne. + +* Un `rsync` basique ne me suffit pas, car je dois pouvoir gérer des modifications des deux côtés de la connexion à la fois, et pouvoir gérer les conflits. diff --git a/samples/timeline.js.html b/samples/timeline.js.html new file mode 100644 index 0000000..3adfbc5 --- /dev/null +++ b/samples/timeline.js.html @@ -0,0 +1,13 @@ + +Pour un projet (dont je reparlerai sûrement bientôt, au passage), j'ai eu besoin de tracer des graphes en JavaScript. Le moyen le plus simple, sachant qu'en plus j'avais besoin d'un peu d'interactivité, était d'utiliser du SVG et de le générer directement en JavaScript.
+ +J'ai donc pensé utiliser une bibliothèque déjà écrite… et c'est là que le bât blesse… On trouve de très bonnes bibliothèques, pour faire de très beaux graphes avec des animations et tout et tout, mais rien de léger, simple et fonctionnel. Je voulais juste tracer des graphes en SVG (potentiellement plusieurs superposés) et avoir des actions personnalisables au clic sur un point. Pas d'animations, ça ne sert à rien, pas de tracés de multiples objets différents en SVG, juste des graphes… Alors, pourquoi charger 30ko de jQuery plus minimum 10ko de Javascript supplémentaires (ça c'était uniquement pour la plus légère, la moyenne était plutôt autour de 70ko supplémentaires) juste pour faire ça ?!?
+ +Du coup, j'ai écrit une petite bibliothèque JavaScript KISS pour tracer des graphes en SVG. Vous pouvez mettre autant de graphes que vous voulez, spécifier le remplissage souhaité, le type de tracé souhaité, et comme c'est du SVG, c'est très simple de binder des événements JavaScript sur vos points (la bibliothèque supporte du clic par défaut, et il y a une petite animation au survol avec une légende). Le tout pour 23ko non compressé (soit moins que jQuery seule, soit dit en passant), et 15ko une fois minifiée, sans aucune dépendance externe. Ça devrait marcher sans problème sur tous les navigateurs décents (pas de fallback compliqué sur du canvas ou autre implémenté par contre) et on peut même descendre sous les 10ko en obfuscant un peu le code.
+ +Voilà, je ne sais pas si ça servira à quelqu'un, mais on sait jamais. Du coup, si ça vous intéresse, ça se récupère ici sur Github et il y a mêmes quelques exemples de démos ici. Le code n'est sûrement pas parfait, mais ça devrait être fonctionnel (et n'hésitez pas à signaler les issues que vous rencontrez). Comme toujours, c'est sous licence SODAWARE : en gros, vous en faites ce que vous voulez, comme vous voulez, mais c'est quand même cool de dire où vous l'avez trouvé (et c'est quand même vraiment pas cool de s'approprier le travail des autres…) et si vous trouvez ma petite bibliothèque utile / fun / cool / whatever et que par hasard on se croise (ou non), vous pouvez me payer un soda (ou plus) :). Et surtout, n'hésitez pas à faire des pull requests ou à me faire signe si vous vous en servez, que je vois tout ce qu'on peut faire avec :)
{kind=link}